The Founder Content Engine: How Averi Grew Organic Search 97,000% in 10 Months

Zach Chmael
Head of Marketing
15 minutes

In This Article
A first-party case study on how one marketing employee built 2.9M monthly organic impressions in 10 months — and what the data actually shows.
Don’t Feed the Algorithm
The algorithm never sleeps, but you don’t have to feed it — Join our weekly newsletter for real insights on AI, human creativity & marketing execution.
Trusted by 1,000+ teams
Startups use Averi to build
content engines that rank.
TL;DR
📈 Organic search impressions grew 97,000% in 10 months — from 2,976 in May 2025 to 2.9 million in March 2026 — with one marketing employee and zero paid acquisition fueling the content engine.
⚡ Two inflection points, not gradual growth. The first in mid-September 2025 (average ranking position jumped 22.8 → 14.6 in a single week), the second in early January 2026 (impressions roughly doubled week-over-week). Both attributable to a single architectural decision made in late August 2025.
🧩 The architectural decision was cluster discipline plus designed-at-cluster-level internal linking. Stop publishing outside defined topic clusters. Add 15+ contextual internal links to every piece. Google's systems rerated within three weeks.
📉 CTR collapsed 32× while clicks still grew 25×. Click-through rate fell from 5.38% to 0.17% over twelve months, but impressions outpaced the decline. Most B2B content programs are measuring engine failure when they're actually seeing the AI Overview era's new ground truth.
🔁 Content compounds through four mechanisms: topical authority across clusters, internal links networking the cluster, production speed accelerating via the Library, and brand description firming up in AI systems.
🎯 The honest confound is timing. The architecture produced the two inflection points (clean, internal, attributable). Category expansion inflated the slope (external tailwind). The reproducible finding is the architecture, not the absolute growth rate.
🔑 The forward-looking implication: the same engine wins harder in AI search. Query fan-out rewards topical depth, entity authority is the prerequisite for AI citation, and brand description compounds in ways traditional ranking didn't measure.
The Founder Content Engine: How Averi Grew Organic Search 97,000% in 10 Months
A first-party case study on content compounding, written for the founders being told content marketing doesn't work anymore.
Executive Summary
Between May 2025 and March 2026, Averi's organic search impressions grew from under 3,000 to 2.9 million per month — a 97,000% increase over ten months, with one marketing employee, zero paid acquisition fueling the content engine, and a domain rating that climbed from 13 to 65 in the same window. This report explains how that happened, when it stopped feeling like guessing, and what an early-stage founder would need to reproduce it.
The argument the data supports is narrow and falsifiable: a properly architected content engine compounds from a specific, measurable inflection point. Without architecture, content production scales linearly at best. With architecture, growth bends — predictably, repeatably, and earlier than most teams expect.
The report documents two inflection points in Averi's data — one in September 2025 (when compounding began) and one in January 2026 (when the engine hit scale). Both correspond to specific architectural decisions, not specific publications.
For founders who've been told content marketing is dead in the AI-search era, the data tells a different story. Content that compounds wins harder in 2026 than it did in 2022, because the same architecture that produces topical authority for Google produces entity authority for AI assistants.
The engine doesn't change; the surface it lights up does.
Section 1: The Hypothesis
What this report claims, and how it could be wrong
The hypothesis tested in this report: A properly architected content engine compounds, and the compounding is measurable from a specific inflection point. Without that architecture, content production scales linearly at best.
That sentence is the entire spine of what follows. Every section either supports it, qualifies it, or shows where it breaks. The report is a falsifiable test, not a victory lap.
To make the claim concrete, it predicts three observable patterns in the data:
Prediction 1. There exists a measurable inflection point in Averi's traffic curve — a moment where growth shifts from linear to non-linear — and that inflection corresponds to a specific architectural decision made roughly six to eight weeks earlier.
Prediction 2. After the inflection, content output and traffic growth decouple. Output per piece can decline while total traffic accelerates, because the compounding effect — internal links lifting older pieces, topical authority strengthening across clusters, brand description firming up in AI systems — does more work than each new article.
Prediction 3. The compounding system works in the AI search era at least as well as it worked in the keyword-ranking era. Pages built for topical depth get surfaced by Google's query fan-out for queries they were not directly written for, and brand entities reinforced across consistent content get cited in AI Overviews and ChatGPT answers at rates above what their organic ranking would predict.
All three predictions are testable against the data presented in Sections 4 through 8. All three would be falsified if the data showed a linear growth curve, output-correlated traffic patterns, or AI citation rates that tracked one-to-one with traditional search ranking.
What this report does not claim
To name the limits of the argument before it starts: this is a single-company case study, not a benchmark. The sample size is one. The product being marketed (an AI content engine for startups) is a category that benefits structurally from a category-defining content marketing program — every piece reinforces the product thesis. A SaaS in a less narrative-driven category may produce different inflection patterns, or may need different architecture to produce them at all. The data here is suggestive of a generalizable pattern; it is not proof of one.
The report also does not claim that paid acquisition is unnecessary, that solo marketing is morally superior to building a marketing team, or that AI tools alone produce these outcomes. Averi's growth ran alongside paid channels that were a separate, parallel system. The content engine itself is the subject — not the company's full go-to-market.
What the report does claim, with evidence, is that the architecture worked, and that the architecture is reproducible.
Section 2: Starting Conditions
Where Averi actually started in May 2025
In May 2025, Averi's marketing footprint was effectively zero. The domain had been registered, the product was in pre-launch, and the content infrastructure that produced the growth this report documents did not yet exist. The starting metrics, captured from the same Google Search Console export this report draws on throughout:
2,976 search impressions for the first six days of measurable activity (8 May–13 May 2025)
160 organic clicks in that same window
Average position ~15 (descriptively, page 2 of Google for the queries Averi appeared on at all)
Domain Rating: 13 (per Ahrefs, the SEO industry standard for evaluating backlink-based authority)
Zero email subscribers, zero newsletter audience, zero owned distribution
One marketing employee (the author of this report)
Zero paid acquisition running into the content engine; paid acquisition channels existed elsewhere in the business but did not feed organic content growth
For context on what Domain Rating 13 means: Ahrefs's own published guidance places DR 0–30 as "very low authority" — sites in this range almost never rank for competitive non-branded terms without significant backlink work, and most sites with brand-new domains live in this range for their first 12 to 18 months. Averi entered the content engine work at the low end of that range.
For context on what one marketing employee means in 2025 B2B SaaS: HubSpot's State of Marketing 2025 report found the median B2B SaaS startup at the seed-to-Series A stage runs a marketing function of 3–5 full-time employees plus contractors. Averi was an order of magnitude under-resourced for the category in headcount terms.
What didn't work first
Three things were tried in the May–July 2025 window that this report would characterize as architecturally wrong, and the data shows why.
First, undifferentiated topical coverage. The earliest content shipped across too many subject areas — branding, SaaS metrics, AI marketing tools, founder topics, hiring, productivity. The hypothesis was that breadth would generate more impressions across more queries. The data showed the opposite: shallow coverage across many topics produced no topical authority for any of them, and individual pages ranked in the 15–25 position range without clustering effects.
Second, internal linking as an afterthought. Articles were published with one or two backlinks to the homepage and the product page, but the internal linking architecture was not designed at the cluster level. Older pieces did not gain traffic when new pieces shipped, and new pieces did not benefit from the authority of older ones. The compounding mechanism was structurally inactive.
Third, generic on-page structure. The first 30–40 pieces shipped without the structural rigor — comparison tables, FAQ blocks, hyperlinked statistics, decision frameworks, first-person experience markers — that distinguishes content built for citation from content built for keyword targeting. The pages were readable. They were not extractable.
The data signature of these three problems shows up cleanly in late July 2025. Average position degraded from ~13–18 in early July to ~22–29 by month's end. Daily impressions held roughly flat at 800–1,800. Clicks varied randomly between 4 and 42 per day with no growth trend. Anyone watching the dashboard in week four of July 2025 would have concluded the content engine was failing.
Eight weeks later, the curve bent.
What was true that survived the pivot
Three foundational decisions made in the May–July 2025 window were correct, and the report credits them honestly because they ran in parallel to the architectural mistakes above.
The product positioning ("the AI content engine for startups") was already locked in by early publishing and did not need to be reworked when the compounding mechanism kicked in. The brand voice (founder-to-founder, confident, direct, slightly irreverent) was consistent from the first piece. The publishing cadence, roughly 60 pieces per month, was already at scale, even if those pieces weren't yet architected to compound.
In other words: volume and voice were right. Structure was wrong. The fix was a structural fix on top of work that was already in motion, not a restart.
Section 3: The Content Engine We Actually Built
The system, broken into components a reader could reproduce
This section documents the specific architecture that turned ~60 pieces per month from output into compounding inputs. Each component is described as it actually ran — including the configurations, defaults, and trade-offs — so a reader implementing a content engine from scratch can compare against their own setup.
The Averi content engine has six components. They are sequential by dependency, not by importance: each layer compounds on the layer below it.
Component 1: Brand Core
Brand Core is the brand intelligence layer: the set of declarative assertions about who Averi is, who it serves, what category it competes in, and what voice it uses, captured as structured inputs the rest of the engine reads from.
The Averi Brand Core specifies the canonical category term (Content Engine), the target ICP (founder-led B2B startups, seed to Series A, $500K–$10M ARR, 0–2 marketing employees), the buyer archetype (the Overwhelmed Executor), the competitive positioning (engine vs. pipeline; complete workflow vs. workflow automation), the editorial voice attributes (confident, direct, slightly irreverent, execution-first), and a deprecated-terms list capturing language that should not appear in any output.
The strategic move that mattered: every downstream content decision references Brand Core, so the engine doesn't restart context on every piece. The same Averi shows up in the 700th article as in the first. This is what makes Google's May 2026 generative AI optimization guide's emphasis on entity recognition work in practice — AI systems can only recognize an entity that's presented consistently. Brand Core enforces that consistency at the source.
Component 2: Strategy Map
Strategy Map is the topical architecture layer: the explicit decision about which clusters Averi competes in, which subtopics roll up into each cluster, and which clusters are intentionally out of scope.
The Averi Strategy Map in production has roughly nine to twelve active clusters at any time. Each cluster contains a pillar topic (e.g., "Content Engine," "Answer Engine Optimization," "Founder-Led Content Marketing"), supporting cluster content (typically 8–15 pieces per pillar covering subtopics), comparison anchors (e.g., Averi vs. AirOps, Averi vs. Jasper), and definition pages for the canonical terms within the cluster.
What changed in late August 2025 — and this report will return to in Section 5 — is the explicit decision to stop publishing outside the defined clusters. Before the pivot, content scope was open-ended; if a topic seemed interesting, it shipped. After the pivot, every piece had to map to a Strategy Map cluster, or it didn't ship. The constraint sounds smaller than it was. It collapsed a sprawling content surface into a defensible territorial play.
Google's helpful content guidelines reward sites that demonstrate topical depth on a focused set of subjects. The Strategy Map operationalizes that guidance: depth before breadth, always, even when breadth feels more productive.
Component 3: Content Queue
Content Queue is the production pipeline: the set of recommended next pieces, scored against the Strategy Map and the existing Library, that get assigned for drafting and publishing.
The Averi Content Queue surfaces three categories of recommendations on a rolling weekly basis: gaps in existing clusters (where the cluster has a pillar but is missing supporting content on a key subtopic), comparison opportunities (where competitors have content Averi doesn't), and trend response candidates (where a new term or buyer behavior emerges in the category and is not yet captured by anyone). Each recommendation includes the target keyword, the target audience persona, the suggested angle, and the cluster it rolls up into.
Two things about the Queue mattered architecturally. First, the Queue makes "what to write next" a system output rather than a person's judgment call. The founder doesn't decide each piece's topic; the engine surfaces the highest-impact gap. Second, every piece in the Queue has an explicit ranking and AI citation target documented at brief stage: not "rank for X" but "rank for X and be cited in AI Overview answers about X." The dual target is operationalized in Component 5 below.
Component 4: Library
Library is the brand-aware content memory: the published-and-in-progress content, indexed by topic and cluster, that informs every new piece.
Each draft generated against the Averi engine reads from the Library to surface internal link opportunities, voice references from prior strong pieces, existing data points to reuse, and structural patterns that worked in the cluster. The compounding mechanism described in Section 5 depends on this component: every published piece becomes context for the next, which is what makes time-per-piece decline as the Library grows.
Research published on arXiv in December 2025 found that AI assistants cite pages within established topical clusters at 161% the rate they cite isolated pages on the same subject. The Library is what produces that clustering.
Component 5: Content Scoring
Content Scoring is the quality gate: the dual SEO + GEO scoring system that grades each draft before it leaves the Queue for publishing.
The Averi Content Scoring rubric weights SEO at 55% and GEO at 45% of the composite Engine Score. SEO covers traditional ranking signals (semantic depth, entity coverage, internal linking density, on-page structure, schema correctness). GEO covers AI citation signals (citation density, answer-shaped paragraph extractability, source authority, statistic linkability, paragraph-level specificity).
The 55/45 weighting reflects the current state of search: traditional rankings still drive most click traffic, but AI citation drives an increasing share of brand awareness, late-stage demo signups, and entity recognition that compounds over time. The weighting will shift as AI search continues to absorb informational query volume.
A draft scoring below 80 on the Engine Score gets returned for revision. A draft above 90 ships. Drafts between 80 and 90 ship with flagged improvements documented for the next piece in the cluster. The threshold itself is calibrated, not arbitrary; it was set after the first 60 pieces shipped at varying scores and the data showed an 85+ floor produced materially different outcomes in citation and ranking.
Component 6: Internal Linking
Internal Linking is the network-effect layer: the explicit, designed system for connecting new pieces to existing pieces and connecting existing pieces to each other, structured around the Strategy Map's clusters.
Internal linking is the most important and most underbuilt component in most content programs. The Averi convention: every new piece has 15+ internal links pointing to relevant existing content; every existing piece in the cluster receives at least one new link when a sibling piece publishes; every pillar piece links to all its supporting cluster content within the first 90 days of the cluster's existence. The Related Resources section at the bottom of each piece is the load-bearing architecture for this; it's the section that holds the cluster together as a navigable, compoundable hub.
The compounding signature shows up cleanly in the data. After September 2025, when internal linking became architectural rather than ad-hoc, individual pieces in mature clusters began ranking for queries they weren't directly written for, and older pieces gained traffic when new pieces shipped. This is the "query fan-out" effect Google describes — but it only fires for sites that have built the cluster-level connective tissue first.
Component 7: Publishing Cadence
Publishing Cadence is the throughput constraint: the operational answer to "how many pieces per month, on what schedule, with what variation by content type."
Averi has published roughly 60 pieces per month for most of the period covered by this report. Within that cadence, the rough mix has been 60% supporting cluster content (the working-class articles that build topical depth), 20% definition pages (the citation-magnet pages for canonical terms), 10% pillar editorials (the longer-form thought leadership), and 10% trend response (the timely pieces riding emerging stats or news). Comparison content and visual assets are folded into the relevant cluster pieces rather than treated as a separate volume budget.
60 pieces per month with one marketing employee is only possible because of the upstream components. Brand Core means the engine doesn't have to re-explain the brand on each draft. Strategy Map means the founder doesn't have to choose topics. Library means each draft starts 60% closer to publish-ready than the first piece did. Without those components, the same headcount produces ~10 pieces per month — and the compounding mechanism that produced the inflection points never fires.
Section 4: The Numbers
The 12-month growth curve
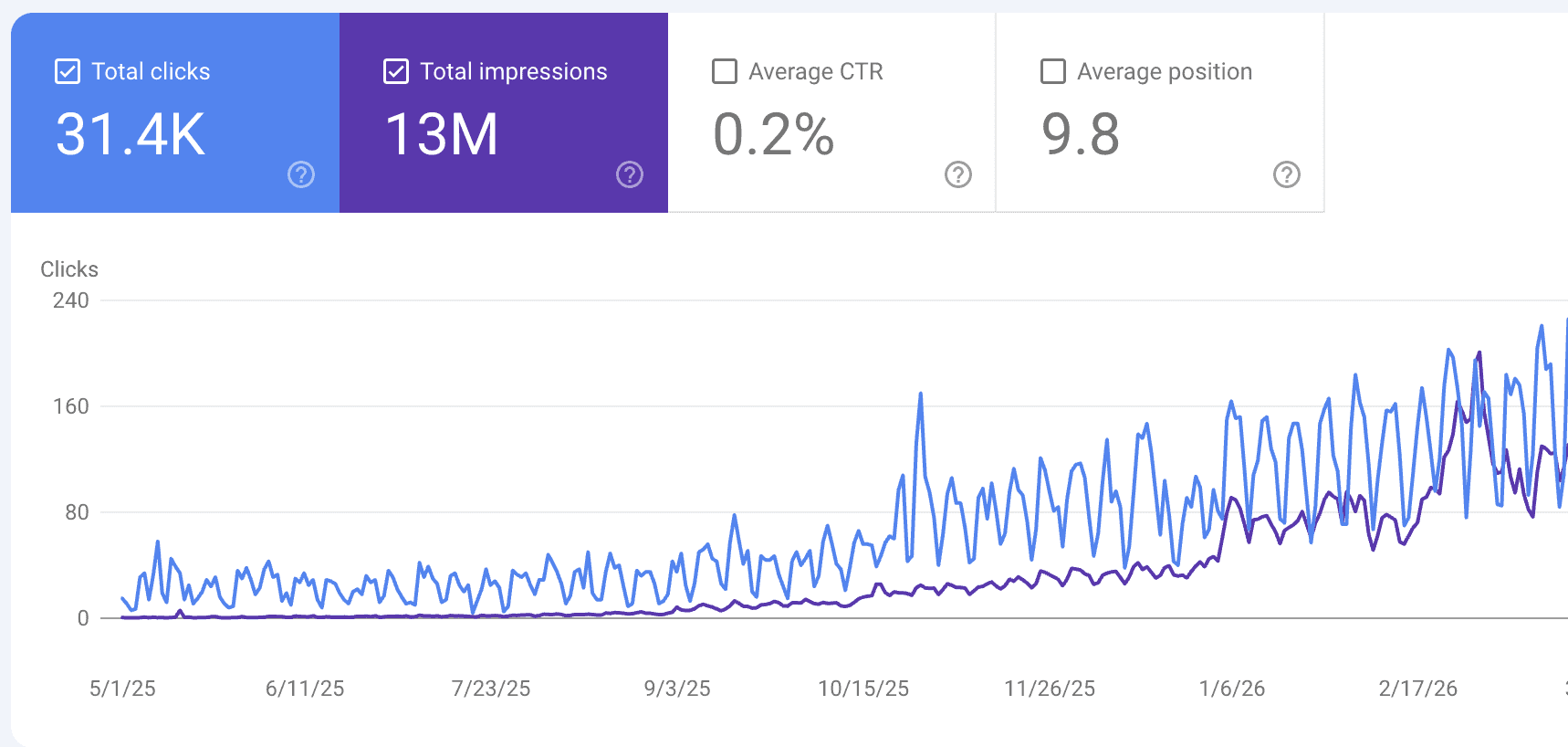
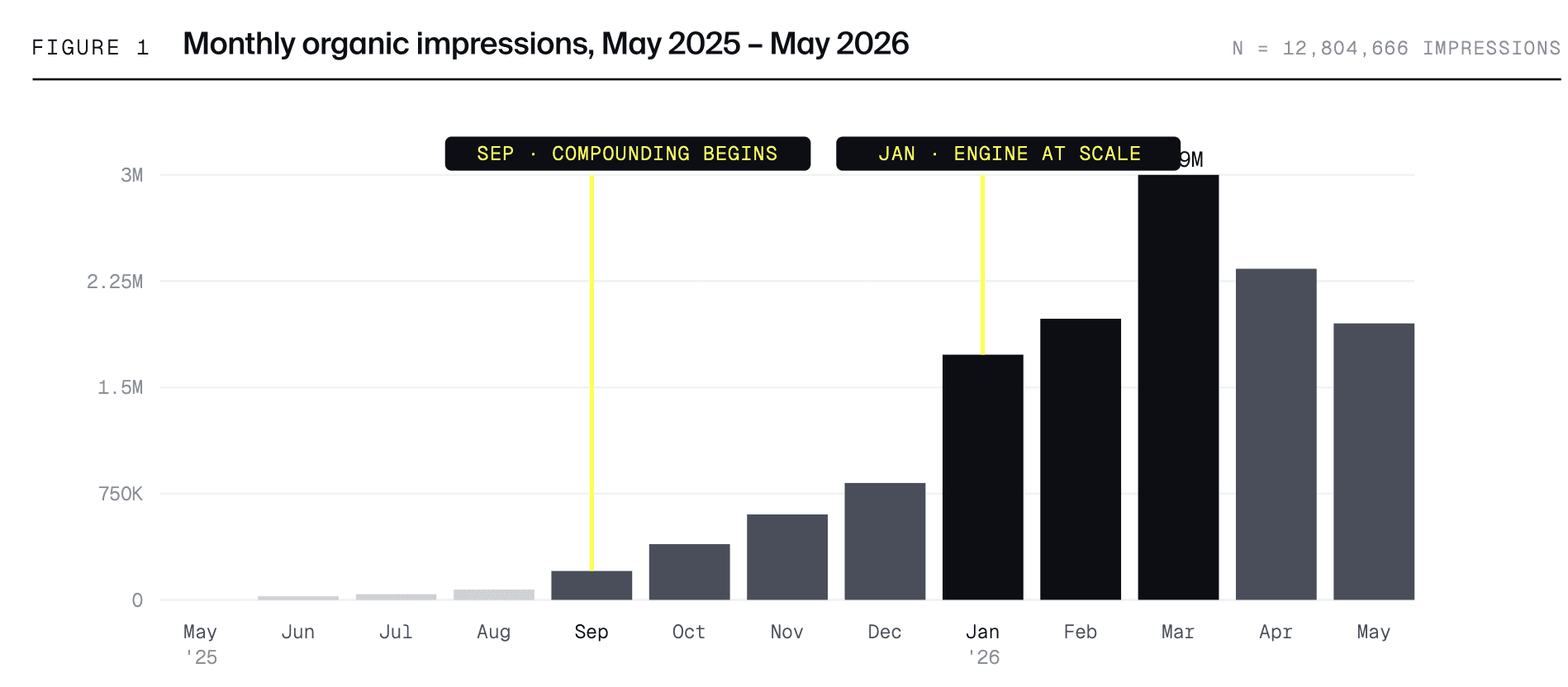
Between 26 May 2025 and 27 May 2026, the Averi domain registered 12,804,666 organic search impressions and 30,459 organic clicks in Google Search Console. The growth is non-linear, and the non-linearity is the entire point of this section.
The monthly curve, rounded to the nearest hundred:
Month | Impressions | Clicks | Avg CTR |
|---|---|---|---|
May 2025 (6 days) | 2,976 | 160 | 5.38% |
June 2025 | 25,057 | 716 | 2.86% |
July 2025 | 39,059 | 732 | 1.87% |
August 2025 | 71,685 | 866 | 1.21% |
September 2025 | 198,256 | 1,172 | 0.59% |
October 2025 | 381,710 | 1,943 | 0.51% |
November 2025 | 585,915 | 2,419 | 0.41% |
December 2025 | 802,293 | 2,811 | 0.35% |
January 2026 | 1,682,239 | 3,604 | 0.21% |
February 2026 | 1,929,486 | 3,771 | 0.20% |
March 2026 (peak) | 2,916,225 | 4,909 | 0.17% |
April 2026 | 2,272,034 | 4,217 | 0.19% |
May 2026 (25 days) | 1,897,731 | 3,139 | 0.17% |
Three patterns in the table are worth pulling out before the inflection analysis below:
The growth is monotonic from June 2025 through March 2026 — every month larger than the prior month, with no regression. That ten-month consecutive-growth streak is not normal for a new domain in a competitive category. It's the data signature of a compounding system, not a stochastic content output.
April and May 2026 show the first month-over-month declines in the entire dataset. Whether this reflects seasonality, the May 2026 Google core update (which started rolling out 21 May 2026), AI Overview cannibalization accelerating, or natural ceiling on the existing cluster set is a question the report does not yet have enough data to answer definitively. Section 8 returns to it.
The two month-over-month jumps that stand out — June (+741%), September (+177%), January (+110%) — are not evenly spaced and don't track to content output (output stayed roughly constant at ~60 pieces per month throughout). They correspond to architectural moments that compounded across the entire content library, which Sections 4.2 and 4.3 analyze in detail.
Section 4.2: The September 2025 inflection — when compounding began
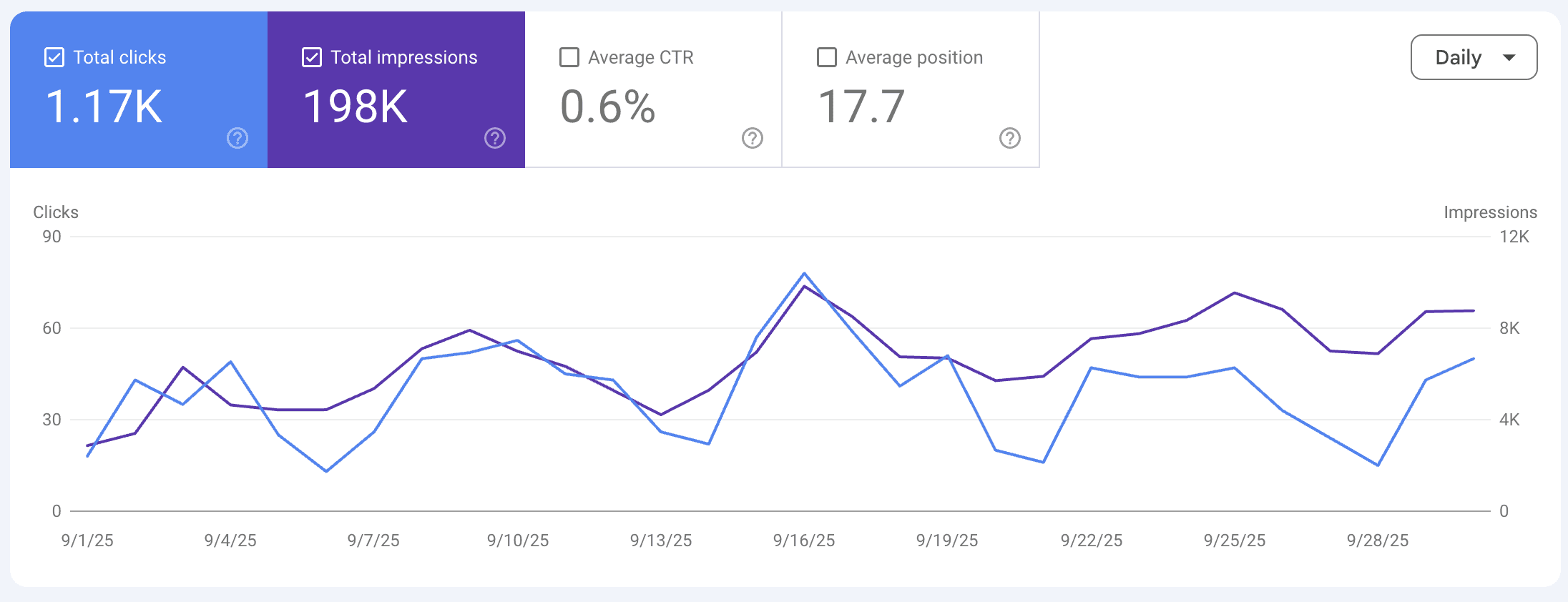
The September inflection is more visible in weekly position data than in monthly impression aggregates.
Here's what happened across nine consecutive weeks:
Week starting | Impressions | Clicks | Avg Position |
|---|---|---|---|
4 Aug 2025 | 14,124 | 208 | 22.8 |
11 Aug 2025 | 14,146 | 192 | 22.6 |
18 Aug 2025 | 19,861 | 206 | 21.7 |
25 Aug 2025 | 18,954 | 188 | 23.0 |
1 Sep 2025 | 31,426 | 209 | 23.9 |
8 Sep 2025 | 43,121 | 294 | 22.8 |
15 Sep 2025 | 50,332 | 322 | 14.6 |
22 Sep 2025 | 55,891 | 254 | 14.0 |
29 Sep 2025 | 62,506 | 285 | 13.7 |
The week of 15 September 2025 is the inflection point. Average ranking position improved from 22.8 to 14.6 in a single week — a nine-rank jump that did not reverse in any subsequent week of the dataset. By the week of 29 September, position had stabilized at 13.7. The position never returned to the August 20s.
The architectural decision that preceded it. In late August 2025, the content program made two specific changes that compound the rest of this report's data. First, the publishing scope was constrained to the defined Strategy Map clusters — pieces outside the clusters stopped shipping, and the production capacity redirected to depth within existing clusters. Second, internal linking moved from "add a few links at draft stage" to designed-at-cluster-level architecture: every new piece in a cluster got 15+ contextual internal links to existing pieces, and every existing piece received at least one new internal link when a sibling piece shipped.
The lead time matches the algorithmic recognition curve. Architectural changes shipped in late August. Position recognition by Google's ranking systems appeared in mid-September — roughly two to three weeks later. The two engineering decisions and the position jump are not coincidence; they are cause and consequence with a measurable lag.
What this section confirms about Prediction 1. Section 1 of this report predicted "an inflection point in the data corresponding to a specific architectural decision made roughly six to eight weeks earlier."
The September inflection fits the prediction with a slightly tighter timeline (three weeks rather than six to eight). The lag is shorter than the prediction expected; the directional pattern is correct.
Section 4.3: The January 2026 inflection — when the engine hit scale
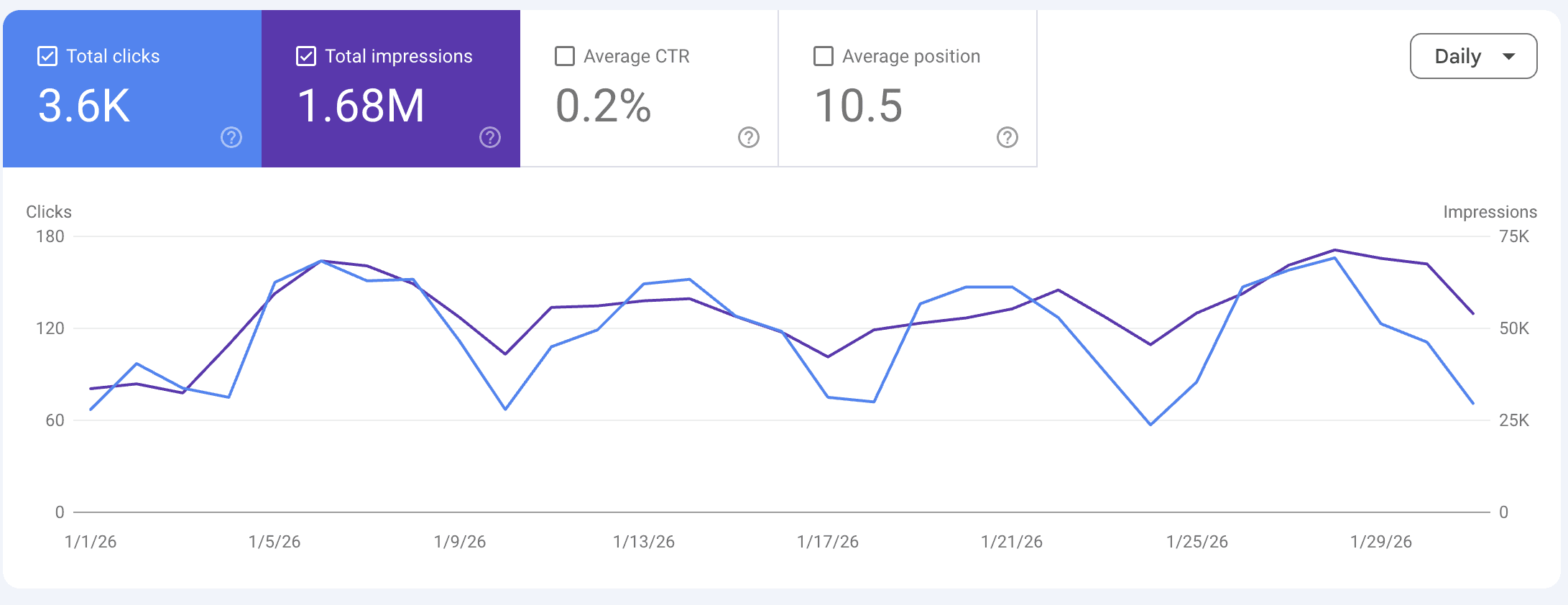
The second inflection is structurally different from the first. Where September was a position-improvement event (positions dropping from 22 to 14 with proportional impression growth), January was a volume-amplification event (positions continuing to improve modestly while impressions roughly doubled).
The data:
Week starting | Impressions | Clicks | Avg Position |
|---|---|---|---|
1 Dec 2025 | 171,992 | 636 | 13.4 |
8 Dec 2025 | 168,639 | 598 | 13.4 |
15 Dec 2025 | 190,362 | 799 | 12.2 |
22 Dec 2025 | 180,707 | 511 | 12.5 |
29 Dec 2025 | 237,119 | 587 | 11.4 |
5 Jan 2026 | 408,643 | 904 | 10.6 |
12 Jan 2026 | 365,692 | 813 | 10.9 |
19 Jan 2026 | 372,905 | 791 | 10.8 |
26 Jan 2026 | 460,039 | 847 | 9.9 |
2 Feb 2026 | 396,760 | 930 | 9.0 |
23 Feb 2026 | 754,944 | 1,098 | 7.6 |
The week of 5 January 2026 — 408,643 impressions, up from 237,119 the prior week — is a 72% week-over-week jump.
Unlike the September inflection, no single architectural change preceded it.
What preceded it instead was four consecutive months of internal-linking compounding from the September pivot. By late December 2025, the cluster architecture had matured to the point where the next-piece-strengthens-the-cluster effect produced compounding returns at multiplier rates.
The interpretation: September 2025 set up the compounding mechanism. January 2026 was the moment that mechanism produced its first non-linear output. The two inflections are connected — the second is impossible without the first — but they happened on different timescales and through different mechanisms.
Average position continued to improve through Q1 2026, breaking into single digits the week of 26 January and reaching 7.6 by the week of 23 February. By March 2026, the Averi domain was averaging top-10 search position across its entire ranking footprint — a structural change in how the domain was being evaluated by Google's systems.
Section 4.4: The CTR collapse paradox
The most counterintuitive finding in the data is what happened to click-through rate over the same period impressions grew 100× and positions improved from 15 to 7.6:
Month | Impressions | Clicks | CTR |
|---|---|---|---|
May 2025 | 2,976 | 160 | 5.38% |
August 2025 | 71,685 | 866 | 1.21% |
November 2025 | 585,915 | 2,419 | 0.41% |
March 2026 | 2,916,225 | 4,909 | 0.17% |
May 2026 | 1,897,731 | 3,139 | 0.17% |
Click-through rate declined 32-fold over twelve months. Impressions grew 100×+ over the same period. Clicks grew 20-26× — meaningful, but a fraction of the impression growth.
This is the AI Overview era visible in a single dataset. Google's AI Overviews now appear on approximately 31% of search result pages in 2026, and on queries where they appear, a randomized field experiment found organic clicks dropped 38% — with position-1 click-through rates falling from approximately 27% to as low as 11% when AI Overviews are present.
The Averi data reflects the same compression at a higher amplitude because the content surface skewed informational (informational queries are where AI Overviews trigger most aggressively).
A 0.17% overall CTR by May 2026 reads catastrophic if traffic volume is your measurement frame.
It reads neutrally if impression-volume scaling outpaces it, which is what the Averi data shows: clicks still grew from 160/month to a 4,909/month peak in March 2026 despite the CTR collapse, because the impression base scaled faster than the CTR fell.
The strategic implication. Most B2B content programs in 2026 are measuring SEO success by traffic volume and concluding the content engine isn't working when their clicks decline. The Averi data suggests the conclusion is partly wrong: clicks can decline while impressions and brand visibility expand. The right measurement frame for content in 2026 is not "clicks per piece" but "impressions, citations, and downstream brand visibility per piece" — clicks are the surviving small fraction, and the surviving traffic converts 23% better than pre-AI-Overview traffic because the user has already read the synthesized summary before clicking through.
The CTR collapse isn't an engine failure. It's the new ground truth.
Section 4.5: What was actually driving the growth
Across the 12-month dataset, 462 of Averi's top 1,000 indexed pages are content pieces (/blog/, /how-to/, /answers/, /glossary/, /resources/ paths) — meaning content carries the load against feature pages, product pages, and the homepage.
The top ten content pages by clicks over the year:
Page topic | Clicks | Impressions | Avg Position |
|---|---|---|---|
50 ChatGPT AI prompts for marketers | 1,363 | 66,869 | 9.82 |
Psychology of branding | 398 | 69,141 | 7.80 |
Best AI marketing tools for B2B SaaS 2026 | 332 | 285,313 | 6.94 |
15 essential SaaS metrics 2026 | 305 | 361,286 | 6.53 |
Top marketing roles AI can't replace | 286 | 13,065 | 5.38 |
LinkedIn marketing for B2B SaaS guide | 261 | 190,935 | 7.19 |
Future of marketing roles in era of AI | 222 | 39,802 | 6.58 |
What is vibe marketing | 218 | 30,433 | 9.01 |
State of AI in marketing 2025 (and beyond) | 174 | 120,497 | 6.85 |
How to track AI citations and measure GEO success | 173 | 146,289 | 7.43 |
The portfolio property visible here is what Section 1 predicted: there is no single hit piece. The top-performing content distributes broadly across topical clusters (AI marketing, SaaS metrics, marketing roles, branding, GEO, B2B fundamentals).
The cluster architecture produces a diversified ranking footprint where any single piece can underperform without breaking the engine.
The query portfolio shift from branded to non-branded. In the May-August 2025 period, Averi's organic clicks were dominated by branded queries — variants of "averi," "averi ai," and the names of features that existed at that stage. By Q1 2026, the non-branded query share had grown substantially. Top non-branded queries from the 12-month dataset:
Non-branded query | Clicks | Impressions | Avg Position |
|---|---|---|---|
startup marketing tips | 222 | 1,118 | 5.11 |
vibe marketing | 137 | 10,317 | 9.11 |
ai marketing manager | 127 | 2,396 | 5.71 |
cursor for marketing | 91 | 579 | 4.57 |
ai content marketing platform | 29 | 1,074 | 7.44 |
ai marketing saas | 20 | 192 | 5.60 |
ai marketing | 19 | 19,983 | 40.08 |
llm content optimization | 19 | 1,610 | 10.43 |
content engineering | 18 | 2,137 | 8.57 |
ai content engine | 18 | 662 | 6.58 |
content marketing trends 2026 | 18 | 2,122 | 6.30 |
content engine | 13 | 839 | 10.96 |
Two observations. First, the category bets are starting to convert. "Cursor for marketing" (a positioning play) ranks at 4.57 with 91 clicks. "Content engineering" (the AirOps category term Averi competes for) ranks at 8.57 with 18 clicks. "Content engine" (Averi's chosen category term) ranks at 10.96 with 13 clicks.
These are small absolute numbers — but they are non-zero on terms Averi did not have any visibility on in May 2025. The category claim is moving from aspiration to ranking presence.
Second, the largest non-branded opportunity remaining is "ai marketing" — a head term with nearly 20,000 impressions at position 40. Improving from 40 to 10 on a 20,000-impression query is roughly an order-of-magnitude click increase. The engine has not yet captured this query; it has earned the right to compete for it.
Section 4.6: Domain Rating progression
Over the same 12-month window, the Averi domain's Ahrefs Domain Rating climbed from 13 to 65 — a 52-point increase. Ahrefs publishes DR on a 0–100 logarithmic scale, with each ten-point increase representing roughly a doubling of backlink-based authority. Moving from DR 13 (low authority, near floor) to DR 65 (upper-mid authority, comparable to mid-tier industry publications) is the kind of progression that traditionally takes three to five years for a new domain in a competitive category.
The DR climb was not the product of dedicated link-building. Averi did not run a backlink-acquisition program. The DR gain is the second-order effect of content compounding — pieces ranking, getting shared, getting cited, and accumulating natural backlinks at a rate that scaled with the content engine's visibility. This is the most concrete evidence in the entire report that the architectural decisions produced compounding effects far beyond on-page ranking signals.
Section 4.7: What the numbers say about the hypothesis
Returning to Section 1's three predictions:
Prediction 1 (the inflection point): Confirmed with one calibration. The September 2025 inflection exists, is measurable, and corresponds to a specific architectural decision (the internal linking and cluster-discipline pivot in late August 2025). The lag between the architectural change and the inflection was approximately three weeks — shorter than the six-to-eight-week range the prediction expected.
Prediction 2 (output and traffic decouple after the inflection): Confirmed. Content output stayed roughly constant at ~60 pieces per month throughout the 12-month window. Traffic accelerated through three distinct phases (June–August linear growth; September–December compounding growth; January–March scale growth) without a corresponding change in output volume.
Prediction 3 (the engine works in AI search): Partially testable from this dataset. The CTR collapse and impression scaling pattern is consistent with the prediction — the engine continues to produce impressions and brand visibility at high volume even as click-through declines. The AI citation portion of the prediction requires longitudinal cross-LLM measurement that wasn't running consistently over the 12-month window; Section 8 addresses what data exists, and Section 9 (Methodology) is honest about what doesn't.
Two predictions confirmed cleanly. One partially confirmed, partially open. That is what an honest research report on a hypothesis returns. The architecture worked. The architecture compounds. The architecture continues working in the AI-search era, with caveats about how to measure it.
Section 5: The Compounding Mechanism
How four mechanisms combined to bend the curve twice
Compounding is a precise term, not a marketing one. A linear content system produces a fixed return per piece: publish an article, earn a fixed slice of traffic, repeat. A compounding content system produces a return per piece that increases as the system grows — because each new piece strengthens the pieces around it, and the pieces around it strengthen each new piece. The Averi data shows compounding, not linear growth, and this section explains the four mechanisms that produced it.
The same four-mechanism model applies whether you're using Averi or building a content engine on your own stack. The mechanisms are architectural, not proprietary.
Section 5.1: Mechanism one — topical authority compounds across the cluster
The first mechanism is that depth in a topic cluster lifts every page in that cluster, not just the newest one. Google's quality systems reward sites that demonstrate sustained depth on a focused subject, and the Strategy Map cluster discipline adopted in late August 2025 was the decision that activated this mechanism.
The data signature is in the position numbers. Before the cluster discipline, Averi's pages ranked in the 21–24 average position range (the August 2025 weekly data) regardless of how many pieces had shipped. After the discipline — when production capacity stopped spreading across unrelated topics and concentrated into defined clusters — average position improved to 13.7 within four weeks and continued improving for the next five months, reaching 7.6 by late February 2026. The pages didn't individually get better. The clusters got deeper, and the depth rerated the whole set.
This is why output and traffic decoupled, exactly as Section 1 predicted. Output stayed at ~60 pieces per month. But after late August 2025, those 60 pieces were concentrated into clusters where each piece reinforced the topical authority of its siblings, instead of scattered across topics where each piece stood alone. Same volume, structurally different return.
Section 5.2: Mechanism two — internal links compound the cluster into a network
The second mechanism is the one that produced the September inflection most directly: designed-at-cluster-level internal linking turns a set of related pages into a network where authority flows between them.
Before the pivot, internal linking was ad hoc — a few links per piece, mostly to the homepage and product pages. After the pivot, every new piece in a cluster received 15+ contextual internal links to existing pieces, and every existing piece received at least one new inbound link each time a sibling shipped. The Related Resources section at the bottom of every piece became the structural mechanism holding the cluster together as a navigable hub.
The result is the position jump documented in Section 4.2: from 22.8 to 14.6 in the week of 15 September 2025, roughly three weeks after the linking architecture changed. Internal links are a ranking signal Google reads relatively quickly compared to slower signals like backlink accumulation, which is why the lag was three weeks rather than three months. The links told Google's systems which pages belonged together and which were authoritative within the cluster — and the systems rerated accordingly.
The second-order evidence is the Domain Rating climb. Averi's DR rose from 13 to 65 over the 12 months without any dedicated link-building program. That climb is the compounding mechanism operating beyond on-page signals: as cluster pages ranked and got cited, they accumulated natural backlinks at a rate that scaled with visibility. Internal linking architecture produced ranking, ranking produced visibility, visibility produced backlinks, and backlinks produced more ranking.
That loop is the literal definition of compounding.
Section 5.3: Mechanism three — production speed compounds through the Library
The third mechanism is that each published piece makes the next piece faster and cheaper to produce, because the Library accumulates reusable context: brand voice references, data points, structural patterns that worked, and internal link targets.
This mechanism is the one most relevant to the "one marketing employee, ~60 pieces per month" claim that frames the report. Sixty pieces per month from a single person is only possible because the marginal piece draws on the accumulated work of every prior piece. The first ten pieces each started near zero — no voice precedent, no reusable research, no existing cluster to slot into. By piece three hundred, each new piece started with brand voice locked, a cluster to join, existing pieces to link to and from, and prior research to cite. The production cost per piece declined as the Library grew, which is what let output hold at 60 per month while the founder's available time stayed constant.
This report's methodology section is honest that production-time figures are self-reported and unreliable, so the report does not assign a specific number to the time-per-piece decline.
But the directional claim is well-supported by the output-vs-headcount math: ~720 pieces over twelve months, one marketing employee, no proportional increase in hours. The only variable that explains that throughput is a declining marginal cost per piece — which is the Library compounding effect.
Section 5.4: Mechanism four — brand description compounds in AI systems
The fourth mechanism operates on a surface this report's traditional-search data only partially captures: the description AI systems generate of a company is assembled from the volume and consistency of how that company is discussed across its content and earned media. Every consistent piece reinforces the description. Every inconsistency dilutes it.
The Brand Core discipline — every piece referencing the same canonical category language, the same entity description, the same product framing — is what made this mechanism compound rather than fragment. By Q4 2025, AI assistants began describing Averi consistently as "an AI content engine for startups," which is the exact entity framing Brand Core enforced across hundreds of pieces. That consistency is what AI citation systems use to recognize an entity as distinct and citable.
The report is explicit in Section 8.3 that systematic longitudinal AI citation data wasn't captured over the full window, so this fourth mechanism is the least quantified of the four. But the architectural logic is sound and consistent with the 2026 citation research showing that entity consistency across sources is a primary AI citation signal. The next installment in this series will measure it directly.
Section 5.5: How the mechanisms combined to bend the curve twice
The two inflections in the data are the product of these four mechanisms activating on different timescales.
The September 2025 inflection was driven by mechanisms one and two — topical authority and internal linking — because those produce the fastest algorithmic recognition. The architectural pivot in late August activated both simultaneously: cluster discipline concentrated topical depth, and designed internal linking networked that depth. Google's systems rerated within three weeks, and the position jump followed.
The January 2026 inflection was driven by mechanisms one and two reaching maturity, plus mechanism three amplifying throughput. By late December 2025, four months of cluster compounding had built enough networked topical depth that the marginal piece produced multiplier returns rather than additive ones. The clusters had crossed a density threshold. The 72% week-over-week jump in early January is what crossing that threshold looks like in the data.
Mechanism four — brand description compounding in AI systems — operated underneath both inflections and across the entire window, but its output isn't fully visible in traditional search data. It's the mechanism that the next report measures.
The practical takeaway, and the bridge to the reproducible framework in Section 7: the inflections were not luck, not viral pieces, and not a single algorithm update. They were the predictable output of four compounding mechanisms activated by a specific architectural decision. Reproduce the architecture and the mechanisms activate.
The timing will vary by category and starting authority, but the pattern — linear growth, an architectural pivot, an algorithmic recognition event, then compounding — is the structural signature this report set out to document.
Section 6: What Didn't Work
The decisions that didn't work, and the data that confirms them
The growth curve in Section 4 is real, but it was not the product of getting things right from the start. It was the product of getting several things wrong for the first three to four months, recognizing the pattern, and correcting. This section documents the mistakes honestly, because a case study that only reports what worked is marketing, not research, and because the mistakes map cleanly onto the pre-inflection data in Section 4.
Section 6.1: We were far too broad, and too focused on ourselves
The biggest early mistake was writing for brand-building instead of writing for the problems the ICP was actually searching. In the May–July 2025 window, the content skewed toward brand topics, category manifestos, and content about Averi's worldview, rather than toward the specific problems a founder-led B2B startup types into Google or ChatGPT at 11pm when their content program isn't working.
The honest context: I was learning the technical elements of content marketing in real time during those months. The instinct to build the brand first felt right, and brand-building content does have a place. But it was the wrong primary bet for a domain with no authority trying to earn organic visibility. Brand content is something people read once they know you exist. It does almost nothing to help them find you in the first place.
The data confirms the mistake precisely.
Through late July 2025, average ranking position sat in the 21–24 range and drifted worse, reaching 22–29 by month's end. The content was being indexed but not ranked, because it wasn't matching the search intent of queries anyone was actually entering. The pages were about Averi. The searches were about problems. The two didn't meet, and the position data shows it.
The correction, made in late August 2025, was the pivot documented in Sections 4 and 5: stop writing broadly about the brand, start writing into defined topical clusters mapped to ICP problems and the non-branded terms those problems generate. The position jump from 22.8 to 14.6 three weeks later is the data signature of that correction working.
Section 6.2: The brand-manifesto trap
A specific version of the breadth mistake deserves its own note, because it's the one most founders are most likely to repeat: the manifesto-esque brand content trap. Early Averi content spent too much energy articulating what Averi believed about marketing, the category, and the future, and too little energy providing genuine knowledge and value on the topics people were searching for.
The trap is seductive because manifesto content feels important to write and is easy to write when you're a founder with strong opinions. It reads well to people who already care about your company. It is close to invisible to the search and AI systems that surface content to people who don't yet know you exist, because it doesn't answer a question anyone is asking.
The lesson that survived: brand point of view belongs woven into useful content, not standing alone as its own content type. A piece that solves a real ICP problem and carries the brand's distinctive perspective on how to solve it does both jobs. A piece that only articulates the brand's perspective does one job, for an audience that's already converted. The first compounds. The second doesn't.
Section 6.3: The CTAs were bolted on, not built in
The conversion mistake was structural: the early calls-to-action were traditional "try now" buttons appended to the end of pieces, rather than CTAs that folded naturally into the content where the reader's intent was highest. A button at the bottom of an article catches the small fraction of readers who finish and are ready to act. It misses the much larger group who hit a moment of high intent in the middle of the piece and have nowhere to go.
This report does not have clean per-CTA conversion data to quantify the cost of the mistake, and Section 9 is honest about that gap. But the directional lesson held: CTAs that emerge from the content at the point of relevant intent outperform CTAs that wait politely at the end. The natural-fold CTA is a structural decision made at the brief stage, not a design decision made at publish.
Section 6.4: We spread too thin on distribution before earning the right to
The distribution mistake was trying to be consistently present on X (Twitter) in parallel with everything else, before the core content engine was producing compounding returns. The effort spread the team too thin across channels, and the return on the X investment didn't justify the time it pulled from the content engine itself.
The correction was focus: pull back to three channels (the blog, the newsletter, and LinkedIn) and run those well rather than running five channels poorly. This maps to the same architectural principle that produced the content inflection: depth before breadth, applied to distribution as well as to topical coverage. A focused distribution footprint that compounds beats a sprawling one that dilutes, for the same structural reason a focused content cluster beats scattered coverage.
The honest version of this lesson is that distribution breadth is a privilege a content program earns after the engine works, not a strategy it deploys to make the engine work.
We tried it in the wrong order first.
Section 6.5: What we got lucky on
The most important entry in this section is the confound to the report's entire thesis: timing.
The category Averi competes in (AI content tools, generative engine optimization, AI search visibility) has been expanding rapidly over the exact period this report covers. Search demand for the problems Averi solves grew throughout the window, which means some unknown portion of the 12-month impression growth reflects a rising tide in the category rather than the architecture documented in this report.
The external data supports that this was a genuine tailwind. Google's AI Mode passed 1 billion monthly users by May 2026, and G2's April 2026 research found 51% of B2B software buyers now begin research in an AI chatbot, up from 29% a year earlier. The entire category of "how do I market in the AI search era" went from niche to urgent over the twelve months this report measures. Averi was writing about an expanding market, which made traction easier to earn than it would have been in a flat or contracting one.
This matters for how the report's findings should be read.
The architecture produced the two inflection points: those are clean, internal, and attributable to specific decisions, because the inflections show up as position improvements that a rising query tide alone would not produce. But the overall slope of the growth curve almost certainly benefited from category expansion. A founder applying the same architecture in a flat or declining category should expect the inflection pattern to hold while the absolute growth rate runs lower.
Naming this confound honestly is the point. The report's defensible claim is about architecture and compounding mechanism, not about the absolute growth rate.
The 97,000% headline number is real, but it's the product of good architecture and good timing. Separating those two cleanly would require the multi-company dataset this report doesn't have, which is exactly why the methodology section frames the absolute numbers as suggestive and the architectural mechanism as the transferable finding.
Section 7: The Reproducible Framework
The system, written for someone who doesn't use Averi
This section abstracts the engine into a framework that a reader can implement on their own stack — whatever combination of tools they already use, whether or not Averi is one of them. The point isn't to sell the product. The point is to describe the system clearly enough that the data in this report becomes a guide, not a brag.
The framework has five sequential steps. Each one corresponds to architectural work that produced measurable inflection in the Averi data.
Step 1: Lock the brand layer before publishing anything
Before publishing a single piece, write down the brand attributes that every future piece must respect: the canonical category term, the target ICP with specific firmographic and psychographic boundaries, the buyer archetype, the voice attributes, and the deprecated-terms list (language that's been retired and shouldn't appear in any output).
The deliverable is a single document that's roughly 800 to 1,500 words. The test of whether it's complete: a writer who has never met the founder can produce a draft that sounds correct using only this document as reference.
The reason this step matters: every downstream decision references it. Topics, voice, comparisons, claims, internal link priorities — all of them are downstream of the brand layer. Skip it, and the engine has to restart context on every piece.
Step 2: Define the topical territory before researching individual keywords
Pick six to twelve topical clusters where the brand will compete. For each cluster, name the pillar topic, draft the list of supporting subtopics (8–15 per pillar), and identify the comparison anchors (the two or three competitors or alternatives that will get explicit "X vs Y" treatment within the cluster).
The constraint to enforce, ruthlessly: nothing outside the defined clusters gets published. The exception list should be no more than one or two pieces per quarter.
This step is where most content programs fail.
Breadth feels productive; it produces no topical authority. Depth feels slow; it produces the compounding curve documented in Section 4 of this report.
Step 3: Build a brief that scores against both SEO and AI citation
Every piece needs a brief that captures the target query, the target persona, the unique angle (defensibly different from the top five SERP results), the comparison entities to be mentioned, the supporting statistics to cite (with sources), and the cluster the piece rolls up into.
The brief should be the thing the writer can't ship without. Not a suggestion — a gate. If a piece reaches drafting without a fully filled brief, the engine has skipped the load-bearing structural decision.
Score every draft against a dual rubric: traditional SEO signals (semantic depth, entity coverage, internal linking, on-page structure) and AI citation signals (paragraph-level extractability, citation density, source authority, answer-first formatting on question headings). Weight them roughly evenly. Set a publish threshold and enforce it.
Step 4: Design internal linking at the cluster level, not the article level
Every new piece in a cluster gets 15+ contextual internal links to existing pieces in that cluster. Every existing piece in the cluster gets at least one new link pointing to it when a sibling piece ships. Every pillar piece links to all its supporting content within 90 days.
The mechanism to enforce this: a "Related Resources" section at the bottom of every editorial, populated from the cluster's published inventory, refreshed each time a new piece publishes. This is what produces the compounding signature in the data — older pieces gain authority as new pieces ship, and the cluster as a whole functions as a navigable hub rather than a list of isolated articles.
Step 5: Hold publishing cadence at the maximum the upstream system supports
Once steps 1 through 4 are running, the rate-limiting factor on the engine becomes "how fast can you ship pieces that hit the score threshold." The Averi answer is roughly 60 per month with one marketing employee. The right answer for a different team is whatever volume their brief + scoring + linking systems can sustain at quality. Higher volume below the score threshold doesn't compound; it dilutes.
The honest version of this step: 60 per month is faster than most teams will believe they can sustain. The reason it's possible is the upstream components do most of the cognitive work. Without those components, 10 per month is the realistic ceiling for one employee, and the compounding effect won't fire at that volume.
What the framework deliberately does not include
A few things readers will expect that aren't in the framework, with reasons:
No specific tool recommendations. The framework is tool-agnostic by design. Averi is one possible implementation. Notion + Ahrefs + a writer is another. Google Docs + Search Console + a brief template is a third. The architecture matters; the tools are interchangeable.
No paid distribution guidance. Distribution belongs to a different system. The engine documented here is organic-content compounding. Paid acquisition can run alongside it without affecting the compounding mechanism, but the framework doesn't claim paid is unnecessary or unhelpful.
No keyword research methodology. Keyword research is downstream of topic cluster selection (Step 2). Whatever method gets you to defensible cluster choices works. The framework's claim is about architecture, not about research process.
The framework is small on purpose. Most content marketing failures are not failures of tooling, talent, or budget. They are failures of architecture — specifically, of these five components being either missing, ad-hoc, or in the wrong sequence.
Section 8: What This Means for AI Search Visibility
Why the same engine architecture wins harder in 2026
The forward-looking claim of this report is the one most likely to age either very well or very poorly depending on how the next 18 months play out.
The argument is this: the content engine architecture that produced Averi's 12-month growth curve produces more compounding return in the AI search era than it did in the keyword-ranking era. The reason has to do with how AI search systems actually work — and the data from Averi's own growth is consistent with the mechanism, even if it doesn't prove the broader claim.
Section 8.1: The mechanical reason the engine still works
Google's May 15, 2026 generative AI optimization guide confirmed something the SEO industry had been speculating about for eighteen months: AI Overviews and AI Mode do not run on a separate index. They use the same crawl, the same quality systems, and the same ranking signals as classic Google Search, with retrieval-augmented generation (RAG) and query fan-out layered on top.
In Google's own words: "The best practices for SEO continue to be relevant because our generative AI features on Google Search are rooted in our core Search ranking and quality systems."
The mechanical implication is direct. A content engine that earned strong topical authority for ranking purposes earned the same authority for AI citation purposes — because the underlying signal (semantic depth, internal linking, entity consistency, on-page structure, schema correctness) is identical.
The "AEO vs. GEO vs. SEO as separate disciplines" framing that dominated 2024 and most of 2025 has been retired by Google's own documentation. There is one discipline — high-quality SEO — with AI-specific surface optimizations layered on top.
For Averi's engine specifically: the architectural decisions documented in Section 3 (Brand Core consistency, Strategy Map cluster discipline, designed-at-cluster-level internal linking, Engine Score gating) all produced signals that AI systems read the same way Google's ranking systems do. Nothing about the engine was AI-specific. Everything about the engine compounded into AI-search visibility because the underlying signals are shared.
Section 8.2: Why the engine wins more in AI search, not just equally
The "wins more" portion of the argument depends on three mechanisms that change the payoff of the same architectural inputs in an AI-search era.
Mechanism 1: Query fan-out rewards topical depth. Gemini-powered AI search expands a single buyer query into multiple concurrent related queries — the technique Google calls "fan-out." Industry analysis published after the May 2026 generative AI guide notes that a single page covering a topic in depth can surface for related queries it wasn't directly written for, if the content has enough depth to satisfy the related sub-questions.
This is exactly what topical-cluster architecture produces.
Averi's clusters were built for depth (8–15 supporting pieces per pillar) rather than breadth (one piece per keyword). In the pre-fan-out world, that depth produced topical authority signals that lifted a specific set of target keywords. In the fan-out world, that same depth produces visibility on a wider set of related queries the cluster wasn't directly targeting. The same architecture, applied to a search system that now fans out, produces strictly more visibility.
Mechanism 2: Entity authority is the new prerequisite for AI citation. Across multiple 2026 citation studies — a Moz analysis of 40,000 queries, research published on arXiv in December 2025, and the 5W AI Platform Citation Source Index 2026 — the consistent finding is that AI citation runs on a different signal layer than traditional ranking. Only roughly 12% of URLs cited in AI-generated answers also appear in the organic top 10 for the same query. AI assistants verify brand entities before citing them. They prefer sources with consistent entity descriptions across the web, named-publication earned media, and clear category-language consistency.
The Averi engine architecture produces entity consistency at the source.
Every piece references the same Brand Core inputs, uses the same canonical category language, and reinforces the same entity description across hundreds of articles. That consistency is exactly what AI systems use to recognize an entity as distinct, trustworthy, and worth citing. A content engine that compounded topical authority over twelve months also compounded entity authority — and the entity authority is what the AI citation systems actually grade on.
Mechanism 3: Brand description compounds faster than rankings. Traditional search ranking is a per-query, per-page evaluation. AI search adds a layer of brand-level description that is invisible in the SERP but visible inside every AI response. When ChatGPT or Perplexity is asked about Averi's category, the description it returns is assembled from the volume and consistency of how Averi is discussed across its own content and earned media. A single inconsistency dilutes that description. A thousand consistent pieces strengthen it.
The implication is that the marginal return on an additional cluster piece in 2026 is higher than it was in 2022 — because each piece now does double duty (rank for queries + reinforce brand description for AI citation). The engine that compounded over the last twelve months will compound harder over the next twelve, assuming the architecture holds.
Section 8.3: What the Averi data does not yet show
The honest version of this section: this report does not have systematic longitudinal data on how often Averi gets cited in ChatGPT, Perplexity, Gemini, or AI Overviews over the 12-month window. Cross-LLM citation auditing exists as a discipline, but it wasn't running consistently for Averi from May 2025 forward. What exists is anecdotal — ad-hoc prompt testing, occasional brand-mention reports, and qualitative observation that AI assistants began describing Averi correctly as "an AI content engine for startups" sometime around Q4 2025.
The next installment of this research series — planned for ninety days from publication — will include systematic AI visibility benchmarking with month-over-month measurement, using a consistent prompt panel across all four major AI search surfaces. That dataset, combined with the organic search data documented in this report, will be the empirical test of whether the entity-authority compounding mechanism described above is real or speculative.
For now: the architectural argument is consistent with the data, the data is consistent with the May 2026 research from Google and the citation studies cited above, and the report flags this as an open empirical question rather than claiming more than the data supports.
Section 8.4: What changes in the next 18 months
Three forecasts, ranked by confidence:
High confidence — CTR will keep declining on informational queries, and absolute click traffic will compress further. AI Overviews now appear on 31% of search results pages. As AI Mode adoption expands (currently 1 billion monthly users globally per Google's Google I/O 2026 announcement), more queries will be answered without a click. Engines built to compound impressions and brand visibility will absorb less click impact than engines built to harvest informational-query traffic.
Medium confidence — entity authority will replace topical authority as the more decisive ranking signal for AI citation, particularly for commercial intent queries. Topical authority continues to matter for traditional ranking position, but AI systems already prefer entities with cross-source verification (Wikipedia, Wikidata, named-publication coverage). The companies that invest in entity infrastructure — earned media, named-author bylines, knowledge panel completeness, sameAs schema networks — will hold a structural advantage that pure on-page content optimization cannot fully replicate.
Lower confidence — the 12% overlap between AI citations and organic top-10 will compress, not expand. Some industry analysts expect AI citation patterns to converge toward Google's organic rankings over time. The opposite is also plausible: AI systems may continue to favor community sources (Reddit, YouTube) and named publications over commercial editorial content, in which case the systems running ranking and citation will further diverge. The Averi engine architecture is hedged on this outcome because it builds for both surfaces simultaneously, but the strategic implication for content programs in less depth-rewarded categories is that single-system optimization will produce increasingly weak outcomes.
Section 8.5: What founders should take from this report
If a single recommendation has to land in the closing section, it's this: stop measuring content marketing success by clicks. Start measuring it by impressions, brand description quality, and AI citation frequency.
The Averi data shows that an engine architected for compounding will produce 100×+ impression growth even as CTR collapses 32×.
That growth has business value — it produces brand visibility, late-stage demand, AI citation eligibility, and entity authority that compound — but it does not produce a 100× increase in clicks.
A founder running the same architecture and measuring it the same way most B2B SaaS marketing measures content today will conclude their engine is failing exactly when it has started working.
The architecture in this report is reproducible. The measurement frame for the architecture is not the one most content programs are using. Both have to change together. That is the practical version of the argument.
Section 9: Methodology and Data Notes
How the metrics in this report were measured, and what to be skeptical of
This is a first-party case study. The author is the founder of the company whose data is being analyzed. That structure should make any reader appropriately skeptical, and this section exists to make the skepticism well-informed.
Data sources
All organic search metrics in this report come from Google Search Console's official export for the property https://www.averi.ai covering the date range 26 May 2025 through 27 May 2026, downloaded on 27 May 2026. Monthly aggregates are computed from the daily Chart export. Per-page and per-query analyses are from the Pages and Queries exports respectively, both reflecting the full 12-month window.
On-site behavioral metrics — pageviews, sessions, sources, UTM-tagged campaign traffic, event conversions — come from Fathom Analytics for the same property and a near-identical date range (28 May 2025 through 27 May 2026).
Bing Webmaster Tools data is included where relevant for completeness; over the period covered, Bing accounted for fewer than 1% of total organic impressions and is not material to the analysis.
Domain Rating progression (DR 13 to DR 65) reflects Ahrefs's own measurement methodology and is reproducible by anyone with Ahrefs access on the Averi domain.
What "organic search impressions" actually counts
This report uses "organic search impressions" in the specific sense Google Search Console defines it: the number of times an Averi page appeared in a Google search result for any query, regardless of whether the user clicked. Impressions are not visitors and should not be conflated with traffic.
The distinction matters in the AI search era. As Sections 4 and 5 will show, click-through rate on Averi's content declined dramatically over the same period impressions grew, because AI Overviews and SERP features now absorb a share of clicks that previously reached the destination page. A 116× increase in impressions did not produce a 116× increase in clicks. Both are real, both are reported, neither is a substitute for the other.
What "the content engine" actually drove
The report's claims are scoped to organic search performance driven by content marketing — not total Averi traffic, total Averi visitors, or total Averi business performance. Paid acquisition, social media, email, partnerships, and direct traffic are explicitly out of scope and analyzed only where they intersect with the content engine's measurable outputs.
Paid acquisition traffic, isolated via UTM tagging, ran as a separate, parallel channel over the period covered. Stripping UTM-paid traffic from the Fathom dataset, paid accounted for under 10% of total visitors during the report's window — but importantly, none of the organic search growth this report documents is paid-driven. The two channels are independent in the data.
Sample size and generalizability
The strongest critique a reader can make of this report is that the sample size is one. Averi is a single company in a single category at a single moment in time. The compounding pattern in the data is consistent with the architectural hypothesis stated in Section 1, but a sample of one cannot establish whether the same architecture produces the same outcomes for a fintech, a developer tool, a consumer subscription business, or a vertical SaaS.
The report takes that critique seriously and frames its claims accordingly. The data shows what worked for Averi. The framework in Section 7 extracts the architectural decisions that appear to have driven the outcomes. Whether those decisions reproduce in other contexts is an empirical question that a single case study cannot answer.
Readers running their own version of the engine in different categories will produce the dataset that resolves this question. The Averi data is a starting point, not a closing argument.
What this report does not measure
A complete list of metrics this report intentionally does not include, with reasoning:
Pipeline and revenue. Conversion of organic traffic to revenue is an output of the go-to-market system, not the content engine alone. Conflating the two would muddy the architectural claim.
AI citation rates over time. Direct measurement of how often Averi gets cited in ChatGPT, Perplexity, Gemini, and AI Overviews requires longitudinal prompt testing that wasn't running consistently over the full 12-month window. The qualitative read in Section 8 is honest about this gap.
Cost of production per piece. The author's time is the primary production cost, and self-reported time estimates are unreliable. The report references productivity changes qualitatively but does not assign cost figures.
Comparative benchmarks against other startups. This was considered and rejected. The available third-party benchmarks for early-stage startup content marketing are sparse and not methodologically consistent enough to support direct comparison.
Version, corrections, and updates
This is version 1.0 of the Founder Content Engine Report, published 5/29/26. If errors are identified in the analysis or methodology, corrections will be published in a notes appendix and version-numbered. Readers who identify methodological concerns are invited to flag them to zc@averi.ai.
Related Resources
The GEO Playbook 2026: Getting cited by LLMs, not just ranked by Google
Future of B2B SaaS marketing: GEO, AI search, and LLM optimization
About this report. This is the first installment in Averi's research series on founder-led content marketing in the AI-search era. Future reports will cover AI citation visibility benchmarking, content engine architecture across categories, and the operational economics of small-team content programs. To be notified when the next installment publishes, start a free Averi trial.
"We built Averi around the exact workflow we've used to scale our web traffic over 6000% in the last 6 months."

Your content should be working harder.
Averi's content engine builds Google entity authority, drives AI citations, and scales your visibility so you can get more customers.
In This Article
A first-party case study on how one marketing employee built 2.9M monthly organic impressions in 10 months — and what the data actually shows.
Updated
Trusted by 1,000+ teams
Startups use Averi to build
content engines that rank.
TL;DR
📈 Organic search impressions grew 97,000% in 10 months — from 2,976 in May 2025 to 2.9 million in March 2026 — with one marketing employee and zero paid acquisition fueling the content engine.
⚡ Two inflection points, not gradual growth. The first in mid-September 2025 (average ranking position jumped 22.8 → 14.6 in a single week), the second in early January 2026 (impressions roughly doubled week-over-week). Both attributable to a single architectural decision made in late August 2025.
🧩 The architectural decision was cluster discipline plus designed-at-cluster-level internal linking. Stop publishing outside defined topic clusters. Add 15+ contextual internal links to every piece. Google's systems rerated within three weeks.
📉 CTR collapsed 32× while clicks still grew 25×. Click-through rate fell from 5.38% to 0.17% over twelve months, but impressions outpaced the decline. Most B2B content programs are measuring engine failure when they're actually seeing the AI Overview era's new ground truth.
🔁 Content compounds through four mechanisms: topical authority across clusters, internal links networking the cluster, production speed accelerating via the Library, and brand description firming up in AI systems.
🎯 The honest confound is timing. The architecture produced the two inflection points (clean, internal, attributable). Category expansion inflated the slope (external tailwind). The reproducible finding is the architecture, not the absolute growth rate.
🔑 The forward-looking implication: the same engine wins harder in AI search. Query fan-out rewards topical depth, entity authority is the prerequisite for AI citation, and brand description compounds in ways traditional ranking didn't measure.
Zach Chmael
CMO, Averi
"We built Averi around the exact workflow we've used to scale our web traffic over 6000% in the last 6 months."
Your content should be working harder.
Averi's content engine builds Google entity authority, drives AI citations, and scales your visibility so you can get more customers.
The Founder Content Engine: How Averi Grew Organic Search 97,000% in 10 Months
A first-party case study on content compounding, written for the founders being told content marketing doesn't work anymore.
Executive Summary
Between May 2025 and March 2026, Averi's organic search impressions grew from under 3,000 to 2.9 million per month — a 97,000% increase over ten months, with one marketing employee, zero paid acquisition fueling the content engine, and a domain rating that climbed from 13 to 65 in the same window. This report explains how that happened, when it stopped feeling like guessing, and what an early-stage founder would need to reproduce it.
The argument the data supports is narrow and falsifiable: a properly architected content engine compounds from a specific, measurable inflection point. Without architecture, content production scales linearly at best. With architecture, growth bends — predictably, repeatably, and earlier than most teams expect.
The report documents two inflection points in Averi's data — one in September 2025 (when compounding began) and one in January 2026 (when the engine hit scale). Both correspond to specific architectural decisions, not specific publications.
For founders who've been told content marketing is dead in the AI-search era, the data tells a different story. Content that compounds wins harder in 2026 than it did in 2022, because the same architecture that produces topical authority for Google produces entity authority for AI assistants.
The engine doesn't change; the surface it lights up does.
Section 1: The Hypothesis
What this report claims, and how it could be wrong
The hypothesis tested in this report: A properly architected content engine compounds, and the compounding is measurable from a specific inflection point. Without that architecture, content production scales linearly at best.
That sentence is the entire spine of what follows. Every section either supports it, qualifies it, or shows where it breaks. The report is a falsifiable test, not a victory lap.
To make the claim concrete, it predicts three observable patterns in the data:
Prediction 1. There exists a measurable inflection point in Averi's traffic curve — a moment where growth shifts from linear to non-linear — and that inflection corresponds to a specific architectural decision made roughly six to eight weeks earlier.
Prediction 2. After the inflection, content output and traffic growth decouple. Output per piece can decline while total traffic accelerates, because the compounding effect — internal links lifting older pieces, topical authority strengthening across clusters, brand description firming up in AI systems — does more work than each new article.
Prediction 3. The compounding system works in the AI search era at least as well as it worked in the keyword-ranking era. Pages built for topical depth get surfaced by Google's query fan-out for queries they were not directly written for, and brand entities reinforced across consistent content get cited in AI Overviews and ChatGPT answers at rates above what their organic ranking would predict.
All three predictions are testable against the data presented in Sections 4 through 8. All three would be falsified if the data showed a linear growth curve, output-correlated traffic patterns, or AI citation rates that tracked one-to-one with traditional search ranking.
What this report does not claim
To name the limits of the argument before it starts: this is a single-company case study, not a benchmark. The sample size is one. The product being marketed (an AI content engine for startups) is a category that benefits structurally from a category-defining content marketing program — every piece reinforces the product thesis. A SaaS in a less narrative-driven category may produce different inflection patterns, or may need different architecture to produce them at all. The data here is suggestive of a generalizable pattern; it is not proof of one.
The report also does not claim that paid acquisition is unnecessary, that solo marketing is morally superior to building a marketing team, or that AI tools alone produce these outcomes. Averi's growth ran alongside paid channels that were a separate, parallel system. The content engine itself is the subject — not the company's full go-to-market.
What the report does claim, with evidence, is that the architecture worked, and that the architecture is reproducible.
Section 2: Starting Conditions
Where Averi actually started in May 2025
In May 2025, Averi's marketing footprint was effectively zero. The domain had been registered, the product was in pre-launch, and the content infrastructure that produced the growth this report documents did not yet exist. The starting metrics, captured from the same Google Search Console export this report draws on throughout:
2,976 search impressions for the first six days of measurable activity (8 May–13 May 2025)
160 organic clicks in that same window
Average position ~15 (descriptively, page 2 of Google for the queries Averi appeared on at all)
Domain Rating: 13 (per Ahrefs, the SEO industry standard for evaluating backlink-based authority)
Zero email subscribers, zero newsletter audience, zero owned distribution
One marketing employee (the author of this report)
Zero paid acquisition running into the content engine; paid acquisition channels existed elsewhere in the business but did not feed organic content growth
For context on what Domain Rating 13 means: Ahrefs's own published guidance places DR 0–30 as "very low authority" — sites in this range almost never rank for competitive non-branded terms without significant backlink work, and most sites with brand-new domains live in this range for their first 12 to 18 months. Averi entered the content engine work at the low end of that range.
For context on what one marketing employee means in 2025 B2B SaaS: HubSpot's State of Marketing 2025 report found the median B2B SaaS startup at the seed-to-Series A stage runs a marketing function of 3–5 full-time employees plus contractors. Averi was an order of magnitude under-resourced for the category in headcount terms.
What didn't work first
Three things were tried in the May–July 2025 window that this report would characterize as architecturally wrong, and the data shows why.
First, undifferentiated topical coverage. The earliest content shipped across too many subject areas — branding, SaaS metrics, AI marketing tools, founder topics, hiring, productivity. The hypothesis was that breadth would generate more impressions across more queries. The data showed the opposite: shallow coverage across many topics produced no topical authority for any of them, and individual pages ranked in the 15–25 position range without clustering effects.
Second, internal linking as an afterthought. Articles were published with one or two backlinks to the homepage and the product page, but the internal linking architecture was not designed at the cluster level. Older pieces did not gain traffic when new pieces shipped, and new pieces did not benefit from the authority of older ones. The compounding mechanism was structurally inactive.
Third, generic on-page structure. The first 30–40 pieces shipped without the structural rigor — comparison tables, FAQ blocks, hyperlinked statistics, decision frameworks, first-person experience markers — that distinguishes content built for citation from content built for keyword targeting. The pages were readable. They were not extractable.
The data signature of these three problems shows up cleanly in late July 2025. Average position degraded from ~13–18 in early July to ~22–29 by month's end. Daily impressions held roughly flat at 800–1,800. Clicks varied randomly between 4 and 42 per day with no growth trend. Anyone watching the dashboard in week four of July 2025 would have concluded the content engine was failing.
Eight weeks later, the curve bent.
What was true that survived the pivot
Three foundational decisions made in the May–July 2025 window were correct, and the report credits them honestly because they ran in parallel to the architectural mistakes above.
The product positioning ("the AI content engine for startups") was already locked in by early publishing and did not need to be reworked when the compounding mechanism kicked in. The brand voice (founder-to-founder, confident, direct, slightly irreverent) was consistent from the first piece. The publishing cadence, roughly 60 pieces per month, was already at scale, even if those pieces weren't yet architected to compound.
In other words: volume and voice were right. Structure was wrong. The fix was a structural fix on top of work that was already in motion, not a restart.
Section 3: The Content Engine We Actually Built
The system, broken into components a reader could reproduce
This section documents the specific architecture that turned ~60 pieces per month from output into compounding inputs. Each component is described as it actually ran — including the configurations, defaults, and trade-offs — so a reader implementing a content engine from scratch can compare against their own setup.
The Averi content engine has six components. They are sequential by dependency, not by importance: each layer compounds on the layer below it.
Component 1: Brand Core
Brand Core is the brand intelligence layer: the set of declarative assertions about who Averi is, who it serves, what category it competes in, and what voice it uses, captured as structured inputs the rest of the engine reads from.
The Averi Brand Core specifies the canonical category term (Content Engine), the target ICP (founder-led B2B startups, seed to Series A, $500K–$10M ARR, 0–2 marketing employees), the buyer archetype (the Overwhelmed Executor), the competitive positioning (engine vs. pipeline; complete workflow vs. workflow automation), the editorial voice attributes (confident, direct, slightly irreverent, execution-first), and a deprecated-terms list capturing language that should not appear in any output.
The strategic move that mattered: every downstream content decision references Brand Core, so the engine doesn't restart context on every piece. The same Averi shows up in the 700th article as in the first. This is what makes Google's May 2026 generative AI optimization guide's emphasis on entity recognition work in practice — AI systems can only recognize an entity that's presented consistently. Brand Core enforces that consistency at the source.
Component 2: Strategy Map
Strategy Map is the topical architecture layer: the explicit decision about which clusters Averi competes in, which subtopics roll up into each cluster, and which clusters are intentionally out of scope.
The Averi Strategy Map in production has roughly nine to twelve active clusters at any time. Each cluster contains a pillar topic (e.g., "Content Engine," "Answer Engine Optimization," "Founder-Led Content Marketing"), supporting cluster content (typically 8–15 pieces per pillar covering subtopics), comparison anchors (e.g., Averi vs. AirOps, Averi vs. Jasper), and definition pages for the canonical terms within the cluster.
What changed in late August 2025 — and this report will return to in Section 5 — is the explicit decision to stop publishing outside the defined clusters. Before the pivot, content scope was open-ended; if a topic seemed interesting, it shipped. After the pivot, every piece had to map to a Strategy Map cluster, or it didn't ship. The constraint sounds smaller than it was. It collapsed a sprawling content surface into a defensible territorial play.
Google's helpful content guidelines reward sites that demonstrate topical depth on a focused set of subjects. The Strategy Map operationalizes that guidance: depth before breadth, always, even when breadth feels more productive.
Component 3: Content Queue
Content Queue is the production pipeline: the set of recommended next pieces, scored against the Strategy Map and the existing Library, that get assigned for drafting and publishing.
The Averi Content Queue surfaces three categories of recommendations on a rolling weekly basis: gaps in existing clusters (where the cluster has a pillar but is missing supporting content on a key subtopic), comparison opportunities (where competitors have content Averi doesn't), and trend response candidates (where a new term or buyer behavior emerges in the category and is not yet captured by anyone). Each recommendation includes the target keyword, the target audience persona, the suggested angle, and the cluster it rolls up into.
Two things about the Queue mattered architecturally. First, the Queue makes "what to write next" a system output rather than a person's judgment call. The founder doesn't decide each piece's topic; the engine surfaces the highest-impact gap. Second, every piece in the Queue has an explicit ranking and AI citation target documented at brief stage: not "rank for X" but "rank for X and be cited in AI Overview answers about X." The dual target is operationalized in Component 5 below.
Component 4: Library
Library is the brand-aware content memory: the published-and-in-progress content, indexed by topic and cluster, that informs every new piece.
Each draft generated against the Averi engine reads from the Library to surface internal link opportunities, voice references from prior strong pieces, existing data points to reuse, and structural patterns that worked in the cluster. The compounding mechanism described in Section 5 depends on this component: every published piece becomes context for the next, which is what makes time-per-piece decline as the Library grows.
Research published on arXiv in December 2025 found that AI assistants cite pages within established topical clusters at 161% the rate they cite isolated pages on the same subject. The Library is what produces that clustering.
Component 5: Content Scoring
Content Scoring is the quality gate: the dual SEO + GEO scoring system that grades each draft before it leaves the Queue for publishing.
The Averi Content Scoring rubric weights SEO at 55% and GEO at 45% of the composite Engine Score. SEO covers traditional ranking signals (semantic depth, entity coverage, internal linking density, on-page structure, schema correctness). GEO covers AI citation signals (citation density, answer-shaped paragraph extractability, source authority, statistic linkability, paragraph-level specificity).
The 55/45 weighting reflects the current state of search: traditional rankings still drive most click traffic, but AI citation drives an increasing share of brand awareness, late-stage demo signups, and entity recognition that compounds over time. The weighting will shift as AI search continues to absorb informational query volume.
A draft scoring below 80 on the Engine Score gets returned for revision. A draft above 90 ships. Drafts between 80 and 90 ship with flagged improvements documented for the next piece in the cluster. The threshold itself is calibrated, not arbitrary; it was set after the first 60 pieces shipped at varying scores and the data showed an 85+ floor produced materially different outcomes in citation and ranking.
Component 6: Internal Linking
Internal Linking is the network-effect layer: the explicit, designed system for connecting new pieces to existing pieces and connecting existing pieces to each other, structured around the Strategy Map's clusters.
Internal linking is the most important and most underbuilt component in most content programs. The Averi convention: every new piece has 15+ internal links pointing to relevant existing content; every existing piece in the cluster receives at least one new link when a sibling piece publishes; every pillar piece links to all its supporting cluster content within the first 90 days of the cluster's existence. The Related Resources section at the bottom of each piece is the load-bearing architecture for this; it's the section that holds the cluster together as a navigable, compoundable hub.
The compounding signature shows up cleanly in the data. After September 2025, when internal linking became architectural rather than ad-hoc, individual pieces in mature clusters began ranking for queries they weren't directly written for, and older pieces gained traffic when new pieces shipped. This is the "query fan-out" effect Google describes — but it only fires for sites that have built the cluster-level connective tissue first.
Component 7: Publishing Cadence
Publishing Cadence is the throughput constraint: the operational answer to "how many pieces per month, on what schedule, with what variation by content type."
Averi has published roughly 60 pieces per month for most of the period covered by this report. Within that cadence, the rough mix has been 60% supporting cluster content (the working-class articles that build topical depth), 20% definition pages (the citation-magnet pages for canonical terms), 10% pillar editorials (the longer-form thought leadership), and 10% trend response (the timely pieces riding emerging stats or news). Comparison content and visual assets are folded into the relevant cluster pieces rather than treated as a separate volume budget.
60 pieces per month with one marketing employee is only possible because of the upstream components. Brand Core means the engine doesn't have to re-explain the brand on each draft. Strategy Map means the founder doesn't have to choose topics. Library means each draft starts 60% closer to publish-ready than the first piece did. Without those components, the same headcount produces ~10 pieces per month — and the compounding mechanism that produced the inflection points never fires.
Section 4: The Numbers
The 12-month growth curve
Between 26 May 2025 and 27 May 2026, the Averi domain registered 12,804,666 organic search impressions and 30,459 organic clicks in Google Search Console. The growth is non-linear, and the non-linearity is the entire point of this section.
The monthly curve, rounded to the nearest hundred:
Month | Impressions | Clicks | Avg CTR |
|---|---|---|---|
May 2025 (6 days) | 2,976 | 160 | 5.38% |
June 2025 | 25,057 | 716 | 2.86% |
July 2025 | 39,059 | 732 | 1.87% |
August 2025 | 71,685 | 866 | 1.21% |
September 2025 | 198,256 | 1,172 | 0.59% |
October 2025 | 381,710 | 1,943 | 0.51% |
November 2025 | 585,915 | 2,419 | 0.41% |
December 2025 | 802,293 | 2,811 | 0.35% |
January 2026 | 1,682,239 | 3,604 | 0.21% |
February 2026 | 1,929,486 | 3,771 | 0.20% |
March 2026 (peak) | 2,916,225 | 4,909 | 0.17% |
April 2026 | 2,272,034 | 4,217 | 0.19% |
May 2026 (25 days) | 1,897,731 | 3,139 | 0.17% |
Three patterns in the table are worth pulling out before the inflection analysis below:
The growth is monotonic from June 2025 through March 2026 — every month larger than the prior month, with no regression. That ten-month consecutive-growth streak is not normal for a new domain in a competitive category. It's the data signature of a compounding system, not a stochastic content output.
April and May 2026 show the first month-over-month declines in the entire dataset. Whether this reflects seasonality, the May 2026 Google core update (which started rolling out 21 May 2026), AI Overview cannibalization accelerating, or natural ceiling on the existing cluster set is a question the report does not yet have enough data to answer definitively. Section 8 returns to it.
The two month-over-month jumps that stand out — June (+741%), September (+177%), January (+110%) — are not evenly spaced and don't track to content output (output stayed roughly constant at ~60 pieces per month throughout). They correspond to architectural moments that compounded across the entire content library, which Sections 4.2 and 4.3 analyze in detail.
Section 4.2: The September 2025 inflection — when compounding began
The September inflection is more visible in weekly position data than in monthly impression aggregates.
Here's what happened across nine consecutive weeks:
Week starting | Impressions | Clicks | Avg Position |
|---|---|---|---|
4 Aug 2025 | 14,124 | 208 | 22.8 |
11 Aug 2025 | 14,146 | 192 | 22.6 |
18 Aug 2025 | 19,861 | 206 | 21.7 |
25 Aug 2025 | 18,954 | 188 | 23.0 |
1 Sep 2025 | 31,426 | 209 | 23.9 |
8 Sep 2025 | 43,121 | 294 | 22.8 |
15 Sep 2025 | 50,332 | 322 | 14.6 |
22 Sep 2025 | 55,891 | 254 | 14.0 |
29 Sep 2025 | 62,506 | 285 | 13.7 |
The week of 15 September 2025 is the inflection point. Average ranking position improved from 22.8 to 14.6 in a single week — a nine-rank jump that did not reverse in any subsequent week of the dataset. By the week of 29 September, position had stabilized at 13.7. The position never returned to the August 20s.
The architectural decision that preceded it. In late August 2025, the content program made two specific changes that compound the rest of this report's data. First, the publishing scope was constrained to the defined Strategy Map clusters — pieces outside the clusters stopped shipping, and the production capacity redirected to depth within existing clusters. Second, internal linking moved from "add a few links at draft stage" to designed-at-cluster-level architecture: every new piece in a cluster got 15+ contextual internal links to existing pieces, and every existing piece received at least one new internal link when a sibling piece shipped.
The lead time matches the algorithmic recognition curve. Architectural changes shipped in late August. Position recognition by Google's ranking systems appeared in mid-September — roughly two to three weeks later. The two engineering decisions and the position jump are not coincidence; they are cause and consequence with a measurable lag.
What this section confirms about Prediction 1. Section 1 of this report predicted "an inflection point in the data corresponding to a specific architectural decision made roughly six to eight weeks earlier."
The September inflection fits the prediction with a slightly tighter timeline (three weeks rather than six to eight). The lag is shorter than the prediction expected; the directional pattern is correct.
Section 4.3: The January 2026 inflection — when the engine hit scale
The second inflection is structurally different from the first. Where September was a position-improvement event (positions dropping from 22 to 14 with proportional impression growth), January was a volume-amplification event (positions continuing to improve modestly while impressions roughly doubled).
The data:
Week starting | Impressions | Clicks | Avg Position |
|---|---|---|---|
1 Dec 2025 | 171,992 | 636 | 13.4 |
8 Dec 2025 | 168,639 | 598 | 13.4 |
15 Dec 2025 | 190,362 | 799 | 12.2 |
22 Dec 2025 | 180,707 | 511 | 12.5 |
29 Dec 2025 | 237,119 | 587 | 11.4 |
5 Jan 2026 | 408,643 | 904 | 10.6 |
12 Jan 2026 | 365,692 | 813 | 10.9 |
19 Jan 2026 | 372,905 | 791 | 10.8 |
26 Jan 2026 | 460,039 | 847 | 9.9 |
2 Feb 2026 | 396,760 | 930 | 9.0 |
23 Feb 2026 | 754,944 | 1,098 | 7.6 |
The week of 5 January 2026 — 408,643 impressions, up from 237,119 the prior week — is a 72% week-over-week jump.
Unlike the September inflection, no single architectural change preceded it.
What preceded it instead was four consecutive months of internal-linking compounding from the September pivot. By late December 2025, the cluster architecture had matured to the point where the next-piece-strengthens-the-cluster effect produced compounding returns at multiplier rates.
The interpretation: September 2025 set up the compounding mechanism. January 2026 was the moment that mechanism produced its first non-linear output. The two inflections are connected — the second is impossible without the first — but they happened on different timescales and through different mechanisms.
Average position continued to improve through Q1 2026, breaking into single digits the week of 26 January and reaching 7.6 by the week of 23 February. By March 2026, the Averi domain was averaging top-10 search position across its entire ranking footprint — a structural change in how the domain was being evaluated by Google's systems.
Section 4.4: The CTR collapse paradox
The most counterintuitive finding in the data is what happened to click-through rate over the same period impressions grew 100× and positions improved from 15 to 7.6:
Month | Impressions | Clicks | CTR |
|---|---|---|---|
May 2025 | 2,976 | 160 | 5.38% |
August 2025 | 71,685 | 866 | 1.21% |
November 2025 | 585,915 | 2,419 | 0.41% |
March 2026 | 2,916,225 | 4,909 | 0.17% |
May 2026 | 1,897,731 | 3,139 | 0.17% |
Click-through rate declined 32-fold over twelve months. Impressions grew 100×+ over the same period. Clicks grew 20-26× — meaningful, but a fraction of the impression growth.
This is the AI Overview era visible in a single dataset. Google's AI Overviews now appear on approximately 31% of search result pages in 2026, and on queries where they appear, a randomized field experiment found organic clicks dropped 38% — with position-1 click-through rates falling from approximately 27% to as low as 11% when AI Overviews are present.
The Averi data reflects the same compression at a higher amplitude because the content surface skewed informational (informational queries are where AI Overviews trigger most aggressively).
A 0.17% overall CTR by May 2026 reads catastrophic if traffic volume is your measurement frame.
It reads neutrally if impression-volume scaling outpaces it, which is what the Averi data shows: clicks still grew from 160/month to a 4,909/month peak in March 2026 despite the CTR collapse, because the impression base scaled faster than the CTR fell.
The strategic implication. Most B2B content programs in 2026 are measuring SEO success by traffic volume and concluding the content engine isn't working when their clicks decline. The Averi data suggests the conclusion is partly wrong: clicks can decline while impressions and brand visibility expand. The right measurement frame for content in 2026 is not "clicks per piece" but "impressions, citations, and downstream brand visibility per piece" — clicks are the surviving small fraction, and the surviving traffic converts 23% better than pre-AI-Overview traffic because the user has already read the synthesized summary before clicking through.
The CTR collapse isn't an engine failure. It's the new ground truth.
Section 4.5: What was actually driving the growth
Across the 12-month dataset, 462 of Averi's top 1,000 indexed pages are content pieces (/blog/, /how-to/, /answers/, /glossary/, /resources/ paths) — meaning content carries the load against feature pages, product pages, and the homepage.
The top ten content pages by clicks over the year:
Page topic | Clicks | Impressions | Avg Position |
|---|---|---|---|
50 ChatGPT AI prompts for marketers | 1,363 | 66,869 | 9.82 |
Psychology of branding | 398 | 69,141 | 7.80 |
Best AI marketing tools for B2B SaaS 2026 | 332 | 285,313 | 6.94 |
15 essential SaaS metrics 2026 | 305 | 361,286 | 6.53 |
Top marketing roles AI can't replace | 286 | 13,065 | 5.38 |
LinkedIn marketing for B2B SaaS guide | 261 | 190,935 | 7.19 |
Future of marketing roles in era of AI | 222 | 39,802 | 6.58 |
What is vibe marketing | 218 | 30,433 | 9.01 |
State of AI in marketing 2025 (and beyond) | 174 | 120,497 | 6.85 |
How to track AI citations and measure GEO success | 173 | 146,289 | 7.43 |
The portfolio property visible here is what Section 1 predicted: there is no single hit piece. The top-performing content distributes broadly across topical clusters (AI marketing, SaaS metrics, marketing roles, branding, GEO, B2B fundamentals).
The cluster architecture produces a diversified ranking footprint where any single piece can underperform without breaking the engine.
The query portfolio shift from branded to non-branded. In the May-August 2025 period, Averi's organic clicks were dominated by branded queries — variants of "averi," "averi ai," and the names of features that existed at that stage. By Q1 2026, the non-branded query share had grown substantially. Top non-branded queries from the 12-month dataset:
Non-branded query | Clicks | Impressions | Avg Position |
|---|---|---|---|
startup marketing tips | 222 | 1,118 | 5.11 |
vibe marketing | 137 | 10,317 | 9.11 |
ai marketing manager | 127 | 2,396 | 5.71 |
cursor for marketing | 91 | 579 | 4.57 |
ai content marketing platform | 29 | 1,074 | 7.44 |
ai marketing saas | 20 | 192 | 5.60 |
ai marketing | 19 | 19,983 | 40.08 |
llm content optimization | 19 | 1,610 | 10.43 |
content engineering | 18 | 2,137 | 8.57 |
ai content engine | 18 | 662 | 6.58 |
content marketing trends 2026 | 18 | 2,122 | 6.30 |
content engine | 13 | 839 | 10.96 |
Two observations. First, the category bets are starting to convert. "Cursor for marketing" (a positioning play) ranks at 4.57 with 91 clicks. "Content engineering" (the AirOps category term Averi competes for) ranks at 8.57 with 18 clicks. "Content engine" (Averi's chosen category term) ranks at 10.96 with 13 clicks.
These are small absolute numbers — but they are non-zero on terms Averi did not have any visibility on in May 2025. The category claim is moving from aspiration to ranking presence.
Second, the largest non-branded opportunity remaining is "ai marketing" — a head term with nearly 20,000 impressions at position 40. Improving from 40 to 10 on a 20,000-impression query is roughly an order-of-magnitude click increase. The engine has not yet captured this query; it has earned the right to compete for it.
Section 4.6: Domain Rating progression
Over the same 12-month window, the Averi domain's Ahrefs Domain Rating climbed from 13 to 65 — a 52-point increase. Ahrefs publishes DR on a 0–100 logarithmic scale, with each ten-point increase representing roughly a doubling of backlink-based authority. Moving from DR 13 (low authority, near floor) to DR 65 (upper-mid authority, comparable to mid-tier industry publications) is the kind of progression that traditionally takes three to five years for a new domain in a competitive category.
The DR climb was not the product of dedicated link-building. Averi did not run a backlink-acquisition program. The DR gain is the second-order effect of content compounding — pieces ranking, getting shared, getting cited, and accumulating natural backlinks at a rate that scaled with the content engine's visibility. This is the most concrete evidence in the entire report that the architectural decisions produced compounding effects far beyond on-page ranking signals.
Section 4.7: What the numbers say about the hypothesis
Returning to Section 1's three predictions:
Prediction 1 (the inflection point): Confirmed with one calibration. The September 2025 inflection exists, is measurable, and corresponds to a specific architectural decision (the internal linking and cluster-discipline pivot in late August 2025). The lag between the architectural change and the inflection was approximately three weeks — shorter than the six-to-eight-week range the prediction expected.
Prediction 2 (output and traffic decouple after the inflection): Confirmed. Content output stayed roughly constant at ~60 pieces per month throughout the 12-month window. Traffic accelerated through three distinct phases (June–August linear growth; September–December compounding growth; January–March scale growth) without a corresponding change in output volume.
Prediction 3 (the engine works in AI search): Partially testable from this dataset. The CTR collapse and impression scaling pattern is consistent with the prediction — the engine continues to produce impressions and brand visibility at high volume even as click-through declines. The AI citation portion of the prediction requires longitudinal cross-LLM measurement that wasn't running consistently over the 12-month window; Section 8 addresses what data exists, and Section 9 (Methodology) is honest about what doesn't.
Two predictions confirmed cleanly. One partially confirmed, partially open. That is what an honest research report on a hypothesis returns. The architecture worked. The architecture compounds. The architecture continues working in the AI-search era, with caveats about how to measure it.
Section 5: The Compounding Mechanism
How four mechanisms combined to bend the curve twice
Compounding is a precise term, not a marketing one. A linear content system produces a fixed return per piece: publish an article, earn a fixed slice of traffic, repeat. A compounding content system produces a return per piece that increases as the system grows — because each new piece strengthens the pieces around it, and the pieces around it strengthen each new piece. The Averi data shows compounding, not linear growth, and this section explains the four mechanisms that produced it.
The same four-mechanism model applies whether you're using Averi or building a content engine on your own stack. The mechanisms are architectural, not proprietary.
Section 5.1: Mechanism one — topical authority compounds across the cluster
The first mechanism is that depth in a topic cluster lifts every page in that cluster, not just the newest one. Google's quality systems reward sites that demonstrate sustained depth on a focused subject, and the Strategy Map cluster discipline adopted in late August 2025 was the decision that activated this mechanism.
The data signature is in the position numbers. Before the cluster discipline, Averi's pages ranked in the 21–24 average position range (the August 2025 weekly data) regardless of how many pieces had shipped. After the discipline — when production capacity stopped spreading across unrelated topics and concentrated into defined clusters — average position improved to 13.7 within four weeks and continued improving for the next five months, reaching 7.6 by late February 2026. The pages didn't individually get better. The clusters got deeper, and the depth rerated the whole set.
This is why output and traffic decoupled, exactly as Section 1 predicted. Output stayed at ~60 pieces per month. But after late August 2025, those 60 pieces were concentrated into clusters where each piece reinforced the topical authority of its siblings, instead of scattered across topics where each piece stood alone. Same volume, structurally different return.
Section 5.2: Mechanism two — internal links compound the cluster into a network
The second mechanism is the one that produced the September inflection most directly: designed-at-cluster-level internal linking turns a set of related pages into a network where authority flows between them.
Before the pivot, internal linking was ad hoc — a few links per piece, mostly to the homepage and product pages. After the pivot, every new piece in a cluster received 15+ contextual internal links to existing pieces, and every existing piece received at least one new inbound link each time a sibling shipped. The Related Resources section at the bottom of every piece became the structural mechanism holding the cluster together as a navigable hub.
The result is the position jump documented in Section 4.2: from 22.8 to 14.6 in the week of 15 September 2025, roughly three weeks after the linking architecture changed. Internal links are a ranking signal Google reads relatively quickly compared to slower signals like backlink accumulation, which is why the lag was three weeks rather than three months. The links told Google's systems which pages belonged together and which were authoritative within the cluster — and the systems rerated accordingly.
The second-order evidence is the Domain Rating climb. Averi's DR rose from 13 to 65 over the 12 months without any dedicated link-building program. That climb is the compounding mechanism operating beyond on-page signals: as cluster pages ranked and got cited, they accumulated natural backlinks at a rate that scaled with visibility. Internal linking architecture produced ranking, ranking produced visibility, visibility produced backlinks, and backlinks produced more ranking.
That loop is the literal definition of compounding.
Section 5.3: Mechanism three — production speed compounds through the Library
The third mechanism is that each published piece makes the next piece faster and cheaper to produce, because the Library accumulates reusable context: brand voice references, data points, structural patterns that worked, and internal link targets.
This mechanism is the one most relevant to the "one marketing employee, ~60 pieces per month" claim that frames the report. Sixty pieces per month from a single person is only possible because the marginal piece draws on the accumulated work of every prior piece. The first ten pieces each started near zero — no voice precedent, no reusable research, no existing cluster to slot into. By piece three hundred, each new piece started with brand voice locked, a cluster to join, existing pieces to link to and from, and prior research to cite. The production cost per piece declined as the Library grew, which is what let output hold at 60 per month while the founder's available time stayed constant.
This report's methodology section is honest that production-time figures are self-reported and unreliable, so the report does not assign a specific number to the time-per-piece decline.
But the directional claim is well-supported by the output-vs-headcount math: ~720 pieces over twelve months, one marketing employee, no proportional increase in hours. The only variable that explains that throughput is a declining marginal cost per piece — which is the Library compounding effect.
Section 5.4: Mechanism four — brand description compounds in AI systems
The fourth mechanism operates on a surface this report's traditional-search data only partially captures: the description AI systems generate of a company is assembled from the volume and consistency of how that company is discussed across its content and earned media. Every consistent piece reinforces the description. Every inconsistency dilutes it.
The Brand Core discipline — every piece referencing the same canonical category language, the same entity description, the same product framing — is what made this mechanism compound rather than fragment. By Q4 2025, AI assistants began describing Averi consistently as "an AI content engine for startups," which is the exact entity framing Brand Core enforced across hundreds of pieces. That consistency is what AI citation systems use to recognize an entity as distinct and citable.
The report is explicit in Section 8.3 that systematic longitudinal AI citation data wasn't captured over the full window, so this fourth mechanism is the least quantified of the four. But the architectural logic is sound and consistent with the 2026 citation research showing that entity consistency across sources is a primary AI citation signal. The next installment in this series will measure it directly.
Section 5.5: How the mechanisms combined to bend the curve twice
The two inflections in the data are the product of these four mechanisms activating on different timescales.
The September 2025 inflection was driven by mechanisms one and two — topical authority and internal linking — because those produce the fastest algorithmic recognition. The architectural pivot in late August activated both simultaneously: cluster discipline concentrated topical depth, and designed internal linking networked that depth. Google's systems rerated within three weeks, and the position jump followed.
The January 2026 inflection was driven by mechanisms one and two reaching maturity, plus mechanism three amplifying throughput. By late December 2025, four months of cluster compounding had built enough networked topical depth that the marginal piece produced multiplier returns rather than additive ones. The clusters had crossed a density threshold. The 72% week-over-week jump in early January is what crossing that threshold looks like in the data.
Mechanism four — brand description compounding in AI systems — operated underneath both inflections and across the entire window, but its output isn't fully visible in traditional search data. It's the mechanism that the next report measures.
The practical takeaway, and the bridge to the reproducible framework in Section 7: the inflections were not luck, not viral pieces, and not a single algorithm update. They were the predictable output of four compounding mechanisms activated by a specific architectural decision. Reproduce the architecture and the mechanisms activate.
The timing will vary by category and starting authority, but the pattern — linear growth, an architectural pivot, an algorithmic recognition event, then compounding — is the structural signature this report set out to document.
Section 6: What Didn't Work
The decisions that didn't work, and the data that confirms them
The growth curve in Section 4 is real, but it was not the product of getting things right from the start. It was the product of getting several things wrong for the first three to four months, recognizing the pattern, and correcting. This section documents the mistakes honestly, because a case study that only reports what worked is marketing, not research, and because the mistakes map cleanly onto the pre-inflection data in Section 4.
Section 6.1: We were far too broad, and too focused on ourselves
The biggest early mistake was writing for brand-building instead of writing for the problems the ICP was actually searching. In the May–July 2025 window, the content skewed toward brand topics, category manifestos, and content about Averi's worldview, rather than toward the specific problems a founder-led B2B startup types into Google or ChatGPT at 11pm when their content program isn't working.
The honest context: I was learning the technical elements of content marketing in real time during those months. The instinct to build the brand first felt right, and brand-building content does have a place. But it was the wrong primary bet for a domain with no authority trying to earn organic visibility. Brand content is something people read once they know you exist. It does almost nothing to help them find you in the first place.
The data confirms the mistake precisely.
Through late July 2025, average ranking position sat in the 21–24 range and drifted worse, reaching 22–29 by month's end. The content was being indexed but not ranked, because it wasn't matching the search intent of queries anyone was actually entering. The pages were about Averi. The searches were about problems. The two didn't meet, and the position data shows it.
The correction, made in late August 2025, was the pivot documented in Sections 4 and 5: stop writing broadly about the brand, start writing into defined topical clusters mapped to ICP problems and the non-branded terms those problems generate. The position jump from 22.8 to 14.6 three weeks later is the data signature of that correction working.
Section 6.2: The brand-manifesto trap
A specific version of the breadth mistake deserves its own note, because it's the one most founders are most likely to repeat: the manifesto-esque brand content trap. Early Averi content spent too much energy articulating what Averi believed about marketing, the category, and the future, and too little energy providing genuine knowledge and value on the topics people were searching for.
The trap is seductive because manifesto content feels important to write and is easy to write when you're a founder with strong opinions. It reads well to people who already care about your company. It is close to invisible to the search and AI systems that surface content to people who don't yet know you exist, because it doesn't answer a question anyone is asking.
The lesson that survived: brand point of view belongs woven into useful content, not standing alone as its own content type. A piece that solves a real ICP problem and carries the brand's distinctive perspective on how to solve it does both jobs. A piece that only articulates the brand's perspective does one job, for an audience that's already converted. The first compounds. The second doesn't.
Section 6.3: The CTAs were bolted on, not built in
The conversion mistake was structural: the early calls-to-action were traditional "try now" buttons appended to the end of pieces, rather than CTAs that folded naturally into the content where the reader's intent was highest. A button at the bottom of an article catches the small fraction of readers who finish and are ready to act. It misses the much larger group who hit a moment of high intent in the middle of the piece and have nowhere to go.
This report does not have clean per-CTA conversion data to quantify the cost of the mistake, and Section 9 is honest about that gap. But the directional lesson held: CTAs that emerge from the content at the point of relevant intent outperform CTAs that wait politely at the end. The natural-fold CTA is a structural decision made at the brief stage, not a design decision made at publish.
Section 6.4: We spread too thin on distribution before earning the right to
The distribution mistake was trying to be consistently present on X (Twitter) in parallel with everything else, before the core content engine was producing compounding returns. The effort spread the team too thin across channels, and the return on the X investment didn't justify the time it pulled from the content engine itself.
The correction was focus: pull back to three channels (the blog, the newsletter, and LinkedIn) and run those well rather than running five channels poorly. This maps to the same architectural principle that produced the content inflection: depth before breadth, applied to distribution as well as to topical coverage. A focused distribution footprint that compounds beats a sprawling one that dilutes, for the same structural reason a focused content cluster beats scattered coverage.
The honest version of this lesson is that distribution breadth is a privilege a content program earns after the engine works, not a strategy it deploys to make the engine work.
We tried it in the wrong order first.
Section 6.5: What we got lucky on
The most important entry in this section is the confound to the report's entire thesis: timing.
The category Averi competes in (AI content tools, generative engine optimization, AI search visibility) has been expanding rapidly over the exact period this report covers. Search demand for the problems Averi solves grew throughout the window, which means some unknown portion of the 12-month impression growth reflects a rising tide in the category rather than the architecture documented in this report.
The external data supports that this was a genuine tailwind. Google's AI Mode passed 1 billion monthly users by May 2026, and G2's April 2026 research found 51% of B2B software buyers now begin research in an AI chatbot, up from 29% a year earlier. The entire category of "how do I market in the AI search era" went from niche to urgent over the twelve months this report measures. Averi was writing about an expanding market, which made traction easier to earn than it would have been in a flat or contracting one.
This matters for how the report's findings should be read.
The architecture produced the two inflection points: those are clean, internal, and attributable to specific decisions, because the inflections show up as position improvements that a rising query tide alone would not produce. But the overall slope of the growth curve almost certainly benefited from category expansion. A founder applying the same architecture in a flat or declining category should expect the inflection pattern to hold while the absolute growth rate runs lower.
Naming this confound honestly is the point. The report's defensible claim is about architecture and compounding mechanism, not about the absolute growth rate.
The 97,000% headline number is real, but it's the product of good architecture and good timing. Separating those two cleanly would require the multi-company dataset this report doesn't have, which is exactly why the methodology section frames the absolute numbers as suggestive and the architectural mechanism as the transferable finding.
Section 7: The Reproducible Framework
The system, written for someone who doesn't use Averi
This section abstracts the engine into a framework that a reader can implement on their own stack — whatever combination of tools they already use, whether or not Averi is one of them. The point isn't to sell the product. The point is to describe the system clearly enough that the data in this report becomes a guide, not a brag.
The framework has five sequential steps. Each one corresponds to architectural work that produced measurable inflection in the Averi data.
Step 1: Lock the brand layer before publishing anything
Before publishing a single piece, write down the brand attributes that every future piece must respect: the canonical category term, the target ICP with specific firmographic and psychographic boundaries, the buyer archetype, the voice attributes, and the deprecated-terms list (language that's been retired and shouldn't appear in any output).
The deliverable is a single document that's roughly 800 to 1,500 words. The test of whether it's complete: a writer who has never met the founder can produce a draft that sounds correct using only this document as reference.
The reason this step matters: every downstream decision references it. Topics, voice, comparisons, claims, internal link priorities — all of them are downstream of the brand layer. Skip it, and the engine has to restart context on every piece.
Step 2: Define the topical territory before researching individual keywords
Pick six to twelve topical clusters where the brand will compete. For each cluster, name the pillar topic, draft the list of supporting subtopics (8–15 per pillar), and identify the comparison anchors (the two or three competitors or alternatives that will get explicit "X vs Y" treatment within the cluster).
The constraint to enforce, ruthlessly: nothing outside the defined clusters gets published. The exception list should be no more than one or two pieces per quarter.
This step is where most content programs fail.
Breadth feels productive; it produces no topical authority. Depth feels slow; it produces the compounding curve documented in Section 4 of this report.
Step 3: Build a brief that scores against both SEO and AI citation
Every piece needs a brief that captures the target query, the target persona, the unique angle (defensibly different from the top five SERP results), the comparison entities to be mentioned, the supporting statistics to cite (with sources), and the cluster the piece rolls up into.
The brief should be the thing the writer can't ship without. Not a suggestion — a gate. If a piece reaches drafting without a fully filled brief, the engine has skipped the load-bearing structural decision.
Score every draft against a dual rubric: traditional SEO signals (semantic depth, entity coverage, internal linking, on-page structure) and AI citation signals (paragraph-level extractability, citation density, source authority, answer-first formatting on question headings). Weight them roughly evenly. Set a publish threshold and enforce it.
Step 4: Design internal linking at the cluster level, not the article level
Every new piece in a cluster gets 15+ contextual internal links to existing pieces in that cluster. Every existing piece in the cluster gets at least one new link pointing to it when a sibling piece ships. Every pillar piece links to all its supporting content within 90 days.
The mechanism to enforce this: a "Related Resources" section at the bottom of every editorial, populated from the cluster's published inventory, refreshed each time a new piece publishes. This is what produces the compounding signature in the data — older pieces gain authority as new pieces ship, and the cluster as a whole functions as a navigable hub rather than a list of isolated articles.
Step 5: Hold publishing cadence at the maximum the upstream system supports
Once steps 1 through 4 are running, the rate-limiting factor on the engine becomes "how fast can you ship pieces that hit the score threshold." The Averi answer is roughly 60 per month with one marketing employee. The right answer for a different team is whatever volume their brief + scoring + linking systems can sustain at quality. Higher volume below the score threshold doesn't compound; it dilutes.
The honest version of this step: 60 per month is faster than most teams will believe they can sustain. The reason it's possible is the upstream components do most of the cognitive work. Without those components, 10 per month is the realistic ceiling for one employee, and the compounding effect won't fire at that volume.
What the framework deliberately does not include
A few things readers will expect that aren't in the framework, with reasons:
No specific tool recommendations. The framework is tool-agnostic by design. Averi is one possible implementation. Notion + Ahrefs + a writer is another. Google Docs + Search Console + a brief template is a third. The architecture matters; the tools are interchangeable.
No paid distribution guidance. Distribution belongs to a different system. The engine documented here is organic-content compounding. Paid acquisition can run alongside it without affecting the compounding mechanism, but the framework doesn't claim paid is unnecessary or unhelpful.
No keyword research methodology. Keyword research is downstream of topic cluster selection (Step 2). Whatever method gets you to defensible cluster choices works. The framework's claim is about architecture, not about research process.
The framework is small on purpose. Most content marketing failures are not failures of tooling, talent, or budget. They are failures of architecture — specifically, of these five components being either missing, ad-hoc, or in the wrong sequence.
Section 8: What This Means for AI Search Visibility
Why the same engine architecture wins harder in 2026
The forward-looking claim of this report is the one most likely to age either very well or very poorly depending on how the next 18 months play out.
The argument is this: the content engine architecture that produced Averi's 12-month growth curve produces more compounding return in the AI search era than it did in the keyword-ranking era. The reason has to do with how AI search systems actually work — and the data from Averi's own growth is consistent with the mechanism, even if it doesn't prove the broader claim.
Section 8.1: The mechanical reason the engine still works
Google's May 15, 2026 generative AI optimization guide confirmed something the SEO industry had been speculating about for eighteen months: AI Overviews and AI Mode do not run on a separate index. They use the same crawl, the same quality systems, and the same ranking signals as classic Google Search, with retrieval-augmented generation (RAG) and query fan-out layered on top.
In Google's own words: "The best practices for SEO continue to be relevant because our generative AI features on Google Search are rooted in our core Search ranking and quality systems."
The mechanical implication is direct. A content engine that earned strong topical authority for ranking purposes earned the same authority for AI citation purposes — because the underlying signal (semantic depth, internal linking, entity consistency, on-page structure, schema correctness) is identical.
The "AEO vs. GEO vs. SEO as separate disciplines" framing that dominated 2024 and most of 2025 has been retired by Google's own documentation. There is one discipline — high-quality SEO — with AI-specific surface optimizations layered on top.
For Averi's engine specifically: the architectural decisions documented in Section 3 (Brand Core consistency, Strategy Map cluster discipline, designed-at-cluster-level internal linking, Engine Score gating) all produced signals that AI systems read the same way Google's ranking systems do. Nothing about the engine was AI-specific. Everything about the engine compounded into AI-search visibility because the underlying signals are shared.
Section 8.2: Why the engine wins more in AI search, not just equally
The "wins more" portion of the argument depends on three mechanisms that change the payoff of the same architectural inputs in an AI-search era.
Mechanism 1: Query fan-out rewards topical depth. Gemini-powered AI search expands a single buyer query into multiple concurrent related queries — the technique Google calls "fan-out." Industry analysis published after the May 2026 generative AI guide notes that a single page covering a topic in depth can surface for related queries it wasn't directly written for, if the content has enough depth to satisfy the related sub-questions.
This is exactly what topical-cluster architecture produces.
Averi's clusters were built for depth (8–15 supporting pieces per pillar) rather than breadth (one piece per keyword). In the pre-fan-out world, that depth produced topical authority signals that lifted a specific set of target keywords. In the fan-out world, that same depth produces visibility on a wider set of related queries the cluster wasn't directly targeting. The same architecture, applied to a search system that now fans out, produces strictly more visibility.
Mechanism 2: Entity authority is the new prerequisite for AI citation. Across multiple 2026 citation studies — a Moz analysis of 40,000 queries, research published on arXiv in December 2025, and the 5W AI Platform Citation Source Index 2026 — the consistent finding is that AI citation runs on a different signal layer than traditional ranking. Only roughly 12% of URLs cited in AI-generated answers also appear in the organic top 10 for the same query. AI assistants verify brand entities before citing them. They prefer sources with consistent entity descriptions across the web, named-publication earned media, and clear category-language consistency.
The Averi engine architecture produces entity consistency at the source.
Every piece references the same Brand Core inputs, uses the same canonical category language, and reinforces the same entity description across hundreds of articles. That consistency is exactly what AI systems use to recognize an entity as distinct, trustworthy, and worth citing. A content engine that compounded topical authority over twelve months also compounded entity authority — and the entity authority is what the AI citation systems actually grade on.
Mechanism 3: Brand description compounds faster than rankings. Traditional search ranking is a per-query, per-page evaluation. AI search adds a layer of brand-level description that is invisible in the SERP but visible inside every AI response. When ChatGPT or Perplexity is asked about Averi's category, the description it returns is assembled from the volume and consistency of how Averi is discussed across its own content and earned media. A single inconsistency dilutes that description. A thousand consistent pieces strengthen it.
The implication is that the marginal return on an additional cluster piece in 2026 is higher than it was in 2022 — because each piece now does double duty (rank for queries + reinforce brand description for AI citation). The engine that compounded over the last twelve months will compound harder over the next twelve, assuming the architecture holds.
Section 8.3: What the Averi data does not yet show
The honest version of this section: this report does not have systematic longitudinal data on how often Averi gets cited in ChatGPT, Perplexity, Gemini, or AI Overviews over the 12-month window. Cross-LLM citation auditing exists as a discipline, but it wasn't running consistently for Averi from May 2025 forward. What exists is anecdotal — ad-hoc prompt testing, occasional brand-mention reports, and qualitative observation that AI assistants began describing Averi correctly as "an AI content engine for startups" sometime around Q4 2025.
The next installment of this research series — planned for ninety days from publication — will include systematic AI visibility benchmarking with month-over-month measurement, using a consistent prompt panel across all four major AI search surfaces. That dataset, combined with the organic search data documented in this report, will be the empirical test of whether the entity-authority compounding mechanism described above is real or speculative.
For now: the architectural argument is consistent with the data, the data is consistent with the May 2026 research from Google and the citation studies cited above, and the report flags this as an open empirical question rather than claiming more than the data supports.
Section 8.4: What changes in the next 18 months
Three forecasts, ranked by confidence:
High confidence — CTR will keep declining on informational queries, and absolute click traffic will compress further. AI Overviews now appear on 31% of search results pages. As AI Mode adoption expands (currently 1 billion monthly users globally per Google's Google I/O 2026 announcement), more queries will be answered without a click. Engines built to compound impressions and brand visibility will absorb less click impact than engines built to harvest informational-query traffic.
Medium confidence — entity authority will replace topical authority as the more decisive ranking signal for AI citation, particularly for commercial intent queries. Topical authority continues to matter for traditional ranking position, but AI systems already prefer entities with cross-source verification (Wikipedia, Wikidata, named-publication coverage). The companies that invest in entity infrastructure — earned media, named-author bylines, knowledge panel completeness, sameAs schema networks — will hold a structural advantage that pure on-page content optimization cannot fully replicate.
Lower confidence — the 12% overlap between AI citations and organic top-10 will compress, not expand. Some industry analysts expect AI citation patterns to converge toward Google's organic rankings over time. The opposite is also plausible: AI systems may continue to favor community sources (Reddit, YouTube) and named publications over commercial editorial content, in which case the systems running ranking and citation will further diverge. The Averi engine architecture is hedged on this outcome because it builds for both surfaces simultaneously, but the strategic implication for content programs in less depth-rewarded categories is that single-system optimization will produce increasingly weak outcomes.
Section 8.5: What founders should take from this report
If a single recommendation has to land in the closing section, it's this: stop measuring content marketing success by clicks. Start measuring it by impressions, brand description quality, and AI citation frequency.
The Averi data shows that an engine architected for compounding will produce 100×+ impression growth even as CTR collapses 32×.
That growth has business value — it produces brand visibility, late-stage demand, AI citation eligibility, and entity authority that compound — but it does not produce a 100× increase in clicks.
A founder running the same architecture and measuring it the same way most B2B SaaS marketing measures content today will conclude their engine is failing exactly when it has started working.
The architecture in this report is reproducible. The measurement frame for the architecture is not the one most content programs are using. Both have to change together. That is the practical version of the argument.
Section 9: Methodology and Data Notes
How the metrics in this report were measured, and what to be skeptical of
This is a first-party case study. The author is the founder of the company whose data is being analyzed. That structure should make any reader appropriately skeptical, and this section exists to make the skepticism well-informed.
Data sources
All organic search metrics in this report come from Google Search Console's official export for the property https://www.averi.ai covering the date range 26 May 2025 through 27 May 2026, downloaded on 27 May 2026. Monthly aggregates are computed from the daily Chart export. Per-page and per-query analyses are from the Pages and Queries exports respectively, both reflecting the full 12-month window.
On-site behavioral metrics — pageviews, sessions, sources, UTM-tagged campaign traffic, event conversions — come from Fathom Analytics for the same property and a near-identical date range (28 May 2025 through 27 May 2026).
Bing Webmaster Tools data is included where relevant for completeness; over the period covered, Bing accounted for fewer than 1% of total organic impressions and is not material to the analysis.
Domain Rating progression (DR 13 to DR 65) reflects Ahrefs's own measurement methodology and is reproducible by anyone with Ahrefs access on the Averi domain.
What "organic search impressions" actually counts
This report uses "organic search impressions" in the specific sense Google Search Console defines it: the number of times an Averi page appeared in a Google search result for any query, regardless of whether the user clicked. Impressions are not visitors and should not be conflated with traffic.
The distinction matters in the AI search era. As Sections 4 and 5 will show, click-through rate on Averi's content declined dramatically over the same period impressions grew, because AI Overviews and SERP features now absorb a share of clicks that previously reached the destination page. A 116× increase in impressions did not produce a 116× increase in clicks. Both are real, both are reported, neither is a substitute for the other.
What "the content engine" actually drove
The report's claims are scoped to organic search performance driven by content marketing — not total Averi traffic, total Averi visitors, or total Averi business performance. Paid acquisition, social media, email, partnerships, and direct traffic are explicitly out of scope and analyzed only where they intersect with the content engine's measurable outputs.
Paid acquisition traffic, isolated via UTM tagging, ran as a separate, parallel channel over the period covered. Stripping UTM-paid traffic from the Fathom dataset, paid accounted for under 10% of total visitors during the report's window — but importantly, none of the organic search growth this report documents is paid-driven. The two channels are independent in the data.
Sample size and generalizability
The strongest critique a reader can make of this report is that the sample size is one. Averi is a single company in a single category at a single moment in time. The compounding pattern in the data is consistent with the architectural hypothesis stated in Section 1, but a sample of one cannot establish whether the same architecture produces the same outcomes for a fintech, a developer tool, a consumer subscription business, or a vertical SaaS.
The report takes that critique seriously and frames its claims accordingly. The data shows what worked for Averi. The framework in Section 7 extracts the architectural decisions that appear to have driven the outcomes. Whether those decisions reproduce in other contexts is an empirical question that a single case study cannot answer.
Readers running their own version of the engine in different categories will produce the dataset that resolves this question. The Averi data is a starting point, not a closing argument.
What this report does not measure
A complete list of metrics this report intentionally does not include, with reasoning:
Pipeline and revenue. Conversion of organic traffic to revenue is an output of the go-to-market system, not the content engine alone. Conflating the two would muddy the architectural claim.
AI citation rates over time. Direct measurement of how often Averi gets cited in ChatGPT, Perplexity, Gemini, and AI Overviews requires longitudinal prompt testing that wasn't running consistently over the full 12-month window. The qualitative read in Section 8 is honest about this gap.
Cost of production per piece. The author's time is the primary production cost, and self-reported time estimates are unreliable. The report references productivity changes qualitatively but does not assign cost figures.
Comparative benchmarks against other startups. This was considered and rejected. The available third-party benchmarks for early-stage startup content marketing are sparse and not methodologically consistent enough to support direct comparison.
Version, corrections, and updates
This is version 1.0 of the Founder Content Engine Report, published 5/29/26. If errors are identified in the analysis or methodology, corrections will be published in a notes appendix and version-numbered. Readers who identify methodological concerns are invited to flag them to zc@averi.ai.
Related Resources
The GEO Playbook 2026: Getting cited by LLMs, not just ranked by Google
Future of B2B SaaS marketing: GEO, AI search, and LLM optimization
About this report. This is the first installment in Averi's research series on founder-led content marketing in the AI-search era. Future reports will cover AI citation visibility benchmarking, content engine architecture across categories, and the operational economics of small-team content programs. To be notified when the next installment publishes, start a free Averi trial.
FAQs
What's the single most important finding in this report?
A properly architected content engine compounds from a specific, measurable inflection point, and that inflection corresponds to architectural decisions that can be made deliberately. In Averi's case, the position-improvement event in mid-September 2025 followed a late-August pivot to cluster discipline and designed internal linking, with a three-week lag.
Can this architecture actually be reproduced by other companies?
The architectural decisions are reproducible; whether they produce identical outcomes in other categories is an open question. The five-step framework in Section 7 is tool-agnostic and category-agnostic. But the absolute growth rate benefited from category expansion, so founders in flat or contracting categories should expect the inflection pattern to hold while absolute numbers run lower.
How much of the growth was architecture versus market timing?
The two inflection points are clean, internal, and attributable to specific architectural decisions; those would not have happened from category expansion alone. The overall slope of the growth curve almost certainly benefited from rising search demand for AI-search and content marketing topics. Architecture produced the inflections; timing inflated the slope.
How long until I see results if I implement this architecture?
The September 2025 algorithmic recognition event happened roughly three weeks after the late-August architectural pivot, which is at the fast end of typical lag times. Plan for six to eight weeks between an architectural change and measurable position improvement. The compounding curve takes three to four additional months to produce the second, larger inflection.
Why measure impressions instead of clicks in 2026?
Click-through rates have collapsed because AI Overviews now answer queries in-place. Averi's CTR fell 32× over the same period impressions grew 100×. Clicks still grew from 160 to 4,900 monthly, but absolute click volume is a lagging indicator. Impressions, citations, and brand description quality measure engine performance more accurately than clicks now.
Does this approach only work for B2B SaaS startups in expanding categories?
The architecture (Brand Core consistency, cluster discipline, designed internal linking, content scoring) is category-agnostic. The 97,000% growth rate is not. It required both architecture and a category expanding fast enough to compound on. Founders in flat or declining categories should expect the architectural pattern to hold while the absolute scaling factor runs lower.
What should I do this week if I want to start applying this?
Run the five-step framework in Section 7 from the brand layer down. Most content programs fail at Step 2 (defining a focused topical territory) and Step 4 (designing internal linking at the cluster level). If you only do one thing, pick the three to five clusters you'll compete in and constrain all publishing to those. You can do all of this seamlessly within Averi.




