Share of AI Voice: How to Measure (and Win) Your Category in ChatGPT, Perplexity, and Google AI Mode

Zach Chmael
Head of Marketing
10 minutes

In This Article
Share of AI voice measures your citation share across ChatGPT, Perplexity, and Google AI Mode. Here's the formula, free workflow, and how to win it.
Updated
Trusted by 1,000+ teams
Startups use Averi to build
content engines that rank.
TL;DR
📐 The formula: (your brand's citations across a defined buyer-intent query set) ÷ (total brand citations across that query set) × 100 = your share of AI voice. Run weekly or biweekly across ChatGPT, Perplexity, Gemini, and Google AI Mode
🆓 You can do it free. 20–50 buyer-intent queries, 3–4 hours weekly, a spreadsheet, and a discipline of running the same query set on the same cadence. Most of the value is in the consistency, not the tooling
💰 The tools that automate it range from $29/mo Otterly Lite to $99/mo Peec AI to $119/mo SE Ranking AI Visibility to $499/mo Profound Lite to $745/mo Semrush AI Toolkit. Choose based on engine coverage (ChatGPT only, vs. ChatGPT + Perplexity + Google AI Mode, vs. full 10-engine coverage)
🎯 Why this metric maps to pipeline when others don't: the query set is the buyer intent. Share normalizes against competition. Citation count alone is vanity, and "AI visibility scores" are made up
🏗️ The compounding mechanic: topical depth beats breadth, cross-source consistency compounds, the signal threshold is 60–90 days. A content engine producing 4–8 focused pieces monthly moves share faster than a multi-tool stack producing 20 scattered pieces
⚠️ The five mistakes that erase the signal: wrong query set, only tracking ChatGPT, not tracking competitors, measuring weekly instead of monthly, optimizing for the score instead of the pipeline behind it
📊 Proof this works: Gruns 2% → 12.6% in 60 days. Rootly 10x citation growth, $126K incremental media value. Lago 50% demo lift from AI search. These outcomes scale across stages from seed-led teams to enterprise marketing

Zach Chmael
CMO, Averi
"We built Averi around the exact workflow we've used to scale our web traffic over 6000% in the last 6 months."
Your content should be working harder.
Averi's content engine builds Google entity authority, drives AI citations, and scales your visibility so you can get more customers.
Share of AI Voice: How to Measure (and Win) Your Category in ChatGPT, Perplexity, and Google AI Mode
Gruns went from 2% to 12.6% share of AI voice in 60 days. Rootly grew their AI citation rate roughly 10x and produced $126K in incremental media value. Lago reported a 50% increase in demos from AI search and 11x AI Overview impressions.
These are revenue outcomes from a metric most B2B SaaS marketing teams aren't measuring yet — and the tool vendors who want to sell you the dashboard for it are racing to define the term before anyone else owns it.
Share of AI voice is the percentage of citations your brand earns across major AI assistants on a defined set of category-relevant queries, compared to competitors. It's the AI-search analogue of traditional share of voice, recalibrated for an environment where AI Overviews answer roughly 48% of B2B SaaS queries and most discovery happens inside an assistant's response rather than on your homepage.
The thing the tool vendors don't tell you: you can calculate a useful version of this metric for free, in roughly three to four hours per week, with a spreadsheet and a query list. The paid tools save time and add depth at scale, but the formula doesn't require their software. The hard part isn't the tooling. It's the discipline to track the right queries and to produce the kind of content that compounds your share over 60–90 days.
This is the practical guide. The formula, the free workflow, the tools that automate it when manual stops scaling, the reason this metric maps to pipeline when others don't, and the compounding mechanic that moves the needle. No tool list pretending to be analysis.
Want to see what your Content ROI could be with a tool that helps you gain share of voice?
What Share Of AI Voice Actually Measures
Most teams calling something "share of AI voice" don't have a precise definition. Tool vendors use the term differently. Industry coverage uses it differently again. The definitional clarity matters because the wrong measurement produces the wrong strategic moves.
The Definition
Share of AI voice is the percentage of cited responses your brand appears in, across a defined set of category-relevant queries run against major AI assistants, compared to competing brands. The "share" comes from dividing your citation count by the total brand citations across the same query set. A 12% share means that across all the brand citations the assistants produced for your query set, your brand was the cited source 12% of the time.
This is structurally similar to traditional share of voice (originally a media-spend ratio) and the broader marketing usage that includes organic search visibility and social mentions. The 2026 version moves the measurement into the AI assistants where buyer research now starts.
Why It's Different From Traditional Share Of Voice
Traditional share of voice measures presence in channels you can buy into (paid media) or earn into (organic rankings). Share of AI voice measures presence inside synthesized AI answers, where the system retrieves passages from your content and decides whether to cite you as a source.
Three operational differences matter:
You can't buy your way in. Paid placement doesn't currently exist in AI Overviews or ChatGPT answers the way it does in Google Ads. Citation is earned through content and brand signals
Position in the answer doesn't equal share. Being one of three citations on a query is different from being the only citation. Share normalizes for citation depth across the response
The query set is the entire game. Pick the wrong queries and you measure the wrong thing. Pick category-relevant buyer-intent queries and the score correlates with pipeline
Why Every Tool Vendor Is Racing To Claim The Term
In Q1 and Q2 2026, every major AI visibility tool launched or rebranded around share of AI voice. Profound positioned its Answer Engine Insights as the enterprise share-of-voice platform. Peec AI and Hall AI surface share of voice metrics explicitly. SE Ranking added AI Visibility Tracking. Otterly, Writesonic, AthenaHQ, and Airefs all market against the term.
The reason: whoever defines the canonical metric owns the category.
Traditional share of voice took decades to standardize across media measurement. The AI version is being standardized in 18 months, and the vendors moving fastest get to be the reference everyone else compares against. The downstream beneficiary is supposed to be the customer, but the practical effect is that most coverage of "share of AI voice" sells you a tool before it teaches you the metric.
This piece reverses that order. The metric first. The tools second.
The Formula
Five steps. The math is straightforward. The discipline of running it the same way every cycle is what produces useful data.
Step 1: Pick 20–50 Buyer-Intent Queries
The query set is the most important decision you make in this entire workflow. Wrong queries produce a vanity score. Right queries produce a pipeline-correlated signal.
The query set should:
Cover the questions a real buyer asks when evaluating solutions in your category
Span the funnel: top-of-funnel awareness queries, mid-funnel comparison queries, bottom-of-funnel decision queries
Include competitor-anchored queries ("X vs Y", "alternatives to X")
Include category-anchored queries ("best [category] for [use case]")
Avoid pure branded queries (those measure brand strength, not category share)
A workable starter set: 20 queries minimum, biased toward mid- and bottom-funnel where AI assistants increasingly intercept buyer research. Larger sets (50–100 queries) produce more stable readings at the cost of more measurement time.
Step 2: Run Each Query Across The Major AI Assistants
Four assistants matter most for B2B SaaS in 2026: ChatGPT, Perplexity, Google AI Mode (formerly AI Overviews on the search results page), and Gemini. Claude is increasingly relevant for technical and developer-oriented categories. Microsoft Copilot matters in enterprise IT-decisioned categories.
The output you're capturing for each query on each assistant: which brands the assistant cited as sources. Not which brands it mentioned in the answer body (that's a different metric, sometimes called "brand mention"). Specifically, which URLs or brand names appear in the citation list, footnote section, or source attribution.
For free measurement, this is a manual paste-and-record exercise. For paid measurement, it's an automated API call running thousands of prompts per day.
Step 3: Count Citations Per Brand
For each query, log the citation count per brand. The simplest schema:
Query | Assistant | Your Brand | Competitor 1 | Competitor 2 | Competitor 3 | Other Brands |
|---|---|---|---|---|---|---|
best AI content engine for startups | ChatGPT | 1 | 0 | 1 | 0 | 3 |
best AI content engine for startups | Perplexity | 0 | 1 | 0 | 1 | 4 |
best AI content engine for startups | Google AI Mode | 1 | 1 | 0 | 0 | 2 |
best AI content engine for startups | Gemini | 0 | 0 | 1 | 0 | 5 |
Across 20 queries × 4 assistants, you produce 80 measurement points per cycle. The aggregation produces the share-of-voice number.
Step 4: Calculate The Percentage
The basic formula:
Share of AI Voice = (Total Your-Brand Citations Across Query Set) ÷ (Total Brand Citations Across Query Set) × 100
Worked example: across 80 measurement points, your brand was cited 28 times, competitor A 35 times, competitor B 22 times, competitor C 19 times, and other brands a combined 144 times.
Total brand citations = 28 + 35 + 22 + 19 + 144 = 248. Your share of AI voice = 28 / 248 = 11.3%.
The same formula runs on competitors so you produce a comparative readout. The ratios between your share and your top competitors' shares are typically more useful than the absolute number, because the "other brands" denominator is noisy across categories.
Step 5: Track Over Time
Single measurements are noise. Trends are signal. Run the same query set, on the same cadence, against the same assistants for at least 90 days before drawing operational conclusions.
A defensible cadence: monthly for the full query set, biweekly for a focused subset (10–15 highest-value queries). Avoid weekly. Assistants update their training data and retrieval indexes on slower-than-weekly cycles, so weekly fluctuations are usually noise rather than signal.
How To Calculate It For Free
Most teams should start manual. The discipline of running the workflow yourself builds the operator intuition that no dashboard substitutes for.
The Weekly Workflow (3–4 Hours)
Open a spreadsheet with columns for query, assistant, your brand citation count, top 3 competitor citation counts, other brand count, notes
Pre-write the query list so you're not generating queries on the fly. Same queries every cycle
Run each query across ChatGPT, Perplexity, Google AI Mode, and Gemini. For each, expand the citation list and log brand counts
Calculate the totals at the bottom of the spreadsheet
Save the cycle as a dated sheet ("Week of YYYY-MM-DD") so historical comparison is straightforward
For a 20-query set across 4 assistants, the time investment is typically 60–90 minutes for the measurement and 30–60 minutes for the analysis and historical comparison. Three to four hours weekly covers it, scaling down as you build pattern recognition.
The Spreadsheet Template
A minimal version has six tabs: Query Set (the list you run every cycle), Cycle Data (the current cycle's raw measurements), Aggregation (the totals and percentages), Trends (cycle-over-cycle), Competitive (your share vs top competitors), and Notes (qualitative observations).
Most teams that build this themselves outgrow it around month three because manual measurement of 20+ queries × 4 assistants × monthly cycles becomes the bottleneck. That's the natural transition point to a paid tool, not the starting point.
When Manual Breaks Down
Manual measurement breaks down when one of three conditions hits:
Query set growth: above ~50 queries, manual measurement consumes more than 4 hours weekly
Assistant expansion: tracking 5+ assistants instead of 4 multiplies the time
Internal reporting requirements: when leadership wants weekly dashboards instead of monthly spreadsheets
At that point, paid tooling pays back its cost by recovering the operator hours.
The Tools That Track It For You
Tool pricing as of May 2026, with the engine coverage and use-case fit each tool is actually best at. This isn't a tool ranking. It's a sizing guide for matching tool to need.
Otterly AI ($29/mo Lite, plus free tier)
The lowest entry point in the AI visibility space, starting at $29/month for the Lite plan with a free tier for basic monitoring. Best for solo founders and small teams who want automated tracking without the enterprise overhead. Coverage spans the major AI engines with white-label options for agencies. Strong on ChatGPT and Perplexity tracking specifically.
Rankability ($79/mo Solo)
$79/month for the Solo plan, positioned for solo operators and small marketing teams. The price point is closer to the small-business segment than the enterprise tools, with feature depth that matches the price.
Peec AI ($99/mo)
$99/month with native GA4 integration, which matters because the GA4 connector lets you correlate AI visibility changes with downstream traffic and conversion impact. Strong on the share-of-voice metric specifically and useful for mid-market teams that want measurement plus attribution.
SE Ranking AI Visibility Tracker ($119/mo)
$119/month and layered on top of a SEO rank tracker many teams already use. Best fit for teams that want traditional SEO rank tracking and AI visibility tracking in one platform, with native GA4 integration.
AthenaHQ (credit-based pricing)
Y Combinator-backed with a founding team from Google and DeepMind and advisors from OpenAI, Anthropic, and DeepMind. The platform centers on an Olympus dashboard showing full AI responses and source citations, with an Action Center that converts insights into specific page-update recommendations. Pricing is credit-based rather than engine-based, which suits teams that need flexible volume rather than fixed engine coverage.
Strongest enterprise case studies in the category: Rootly's 10x citation growth and $126K incremental media value, Lago's 50% demo lift, Gruns' 2% → 12.6% in 60 days.
Scrunch AI ($300/mo)
$300/month for 350 prompts. Mid-market positioning with depth that fits content marketing teams running structured citation analysis.
Profound ($499/mo Lite)
Profound starts at $499/month for the Lite tier and offers Growth at $399/month with 3 engines, 100 prompts, 9,000 responses, and 3 seats, scaling to Enterprise with up to 10 engines and SOC 2 Type II. Profound's Answer Engine Insights module runs over 15 million prompts per day, the highest data volume in the category. Coverage scales by tier: Starter covers ChatGPT only, Growth adds Perplexity and Google AI Overviews, Enterprise covers the full 10-engine set. Best for enterprise teams with budget and analyst capacity for ongoing AI answer monitoring at scale.
Ahrefs Brand Radar ($699/mo)
$699/month as an add-on to the Ahrefs SEO platform. Best for teams already on Ahrefs who want AI visibility tracking integrated into their existing SEO workflow rather than as a separate platform.
Semrush AI Toolkit ($745/mo)
Around $745/month, part of the larger Semrush platform. Same logic as Ahrefs: integrated SEO and AI visibility in one place, at a price point that fits enterprise teams already using Semrush as their primary SEO infrastructure.
When To Invest Vs. Stay Manual
The simplest decision rule: stay manual while the query set is under 50 and the cadence is monthly. Invest in tooling when one of the three breakdown conditions hits (query set growth, assistant expansion, or internal reporting needs).
The progression most B2B SaaS teams follow:
Months 0–3: free manual measurement, 20–30 queries, monthly cycle
Months 3–6: expand to 40–60 queries if pipeline correlation is showing up
Months 6+: invest in $29–$119/month tooling (Otterly, Peec AI, or SE Ranking AI Visibility) when manual scaling breaks
Growth stage: move to $300–$745/month tooling (Profound, Ahrefs Brand Radar, Semrush AI Toolkit) when integrated reporting becomes the constraint
Our honest review of the full AI search visibility tracker market with use-case fit guidance is here.
Why Share Of AI Voice Is The Only AI Metric That Maps To Pipeline
Most AI search metrics in 2026 are either vanity (citation count alone), made up (proprietary "AI visibility scores"), or too narrow (single-assistant tracking). Share of AI voice is the metric that maps to pipeline because of three structural properties the other metrics don't have.
The Query Set Is The Buyer Intent
Citation count without context is a vanity metric. A brand can have hundreds of citations on irrelevant queries (random feature mentions, archived blog references, edge-case explanations) and produce zero pipeline. Share of AI voice solves this because the metric is anchored to a query set you defined as buyer-intent. If your queries map to actual buyer decisions, the citations you earn on those queries correlate with the buyers who will encounter your brand during research.
This is the same logic that makes targeted SEO better than generic SEO. The questions matter more than the counts.
Share Normalizes Against Competition
A raw citation count tells you nothing about whether you're winning or losing. Competitor A might have 28 citations because you have 28. Competitor A might have 280 citations because you have 28. The strategic implication is entirely different in each case, but the raw count looks the same.
Share normalizes this. A 12% share against a top competitor at 18% is a clear competitive position. A 12% share against a top competitor at 35% is a different position requiring different moves. The denominator (total brand citations across the query set) is what makes the metric strategically useful rather than just descriptive.
"AI Visibility Scores" Are Made Up
Several tool vendors invented proprietary "AI visibility scores" that combine citation count, position, sentiment, brand mention, and other signals into a single number. The numbers don't translate across vendors. Vendor A's "AI visibility score" of 73 doesn't mean anything against vendor B's "visibility index" of 84.
Share of AI voice is reproducible across vendors because the formula is portable. You can calculate it from any vendor's raw data, or from manual measurement, and the percentage means the same thing in any context. This portability is what makes it a real metric rather than a vendor lock-in mechanism.
Pipeline Correlation In Practice
The case studies from the tools market document the pipeline correlation. AthenaHQ's published case studies show Rootly's ~10x citation rate growth produced $126K in incremental media value. Lago's 50% increase in demos from AI search came alongside 11x AI Overview impression growth. Gruns' 2% → 12.6% share of AI voice in 60 days came with measurable downstream lead and pipeline impact.
These aren't outliers cherry-picked for marketing. They're the kind of outcomes that show up consistently when a team picks the right query set, measures over enough time, and produces content that compounds the share.
How To Win Share Of AI Voice (The Compounding Mechanic)
Measuring share is useful. Moving share is the actual goal. Four operational moves compound the metric over 60–90 days.
Topical Depth Beats Topical Breadth
The teams that win share of AI voice publish deeply into 3–5 focused topic clusters rather than broadly across 20 disconnected topics. The reason is technical: RAG retrieval (the mechanism behind AI Overviews and most AI search citation) rewards cross-page consistency on a topic. A site with 30 pieces deeply covering AI content workflows outperforms a site with 300 pieces shallowly covering everything in marketing.
The argument for topical depth in detail is here.
Cross-Source Consistency Compounds
AI assistants weight sources higher when the brand's positioning is consistent across multiple cited references. If your website, your earned media, your G2 profile, and your industry analyst coverage all describe you the same way, the assistants treat that consistency as a brand-strength signal. If your positioning shifts across sources, the inconsistency reduces citation weight.
This is the under-discussed reason 85% of non-paid AI citations come from earned media (industry analysis, publications, third-party reviews). The earned media reinforces the on-site positioning, and the consistency compounds the share signal.
The 60–90 Day Signal Threshold
Share of AI voice doesn't move on a weekly timescale. The training data and retrieval indexes underneath the major assistants update on slower cycles. Realistic timelines for share-of-voice movement:
Days 0–30: baseline measurement, no expected movement
Days 30–60: early movement on competitive query subsets if content velocity is consistent
Days 60–90: meaningful share movement on most query sets if content is compounding
Days 90+: stable trend with monthly variance, useful for strategic decision-making
Teams that expect weekly movement give up before the metric stabilizes. The 60–90 day patience is what separates the case studies (Gruns, Rootly, Lago) from the teams that quit at week three.
What Proof Looks Like
The three case studies worth internalizing as benchmarks for "what good looks like":
Gruns: 2% → 12.6% share of AI voice in 60 days. The fastest documented movement at small-team scale.
Rootly: ~10x citation rate growth and $126K incremental media value. The clearest dollar-attribution case study.
Lago: 50% increase in demos from AI search and 11x AI Overview impressions. The cleanest pipeline correlation.
These outcomes scale from solo-founder to small-team stages, which is the segment most likely to be reading this piece. They're not enterprise-only benchmarks.
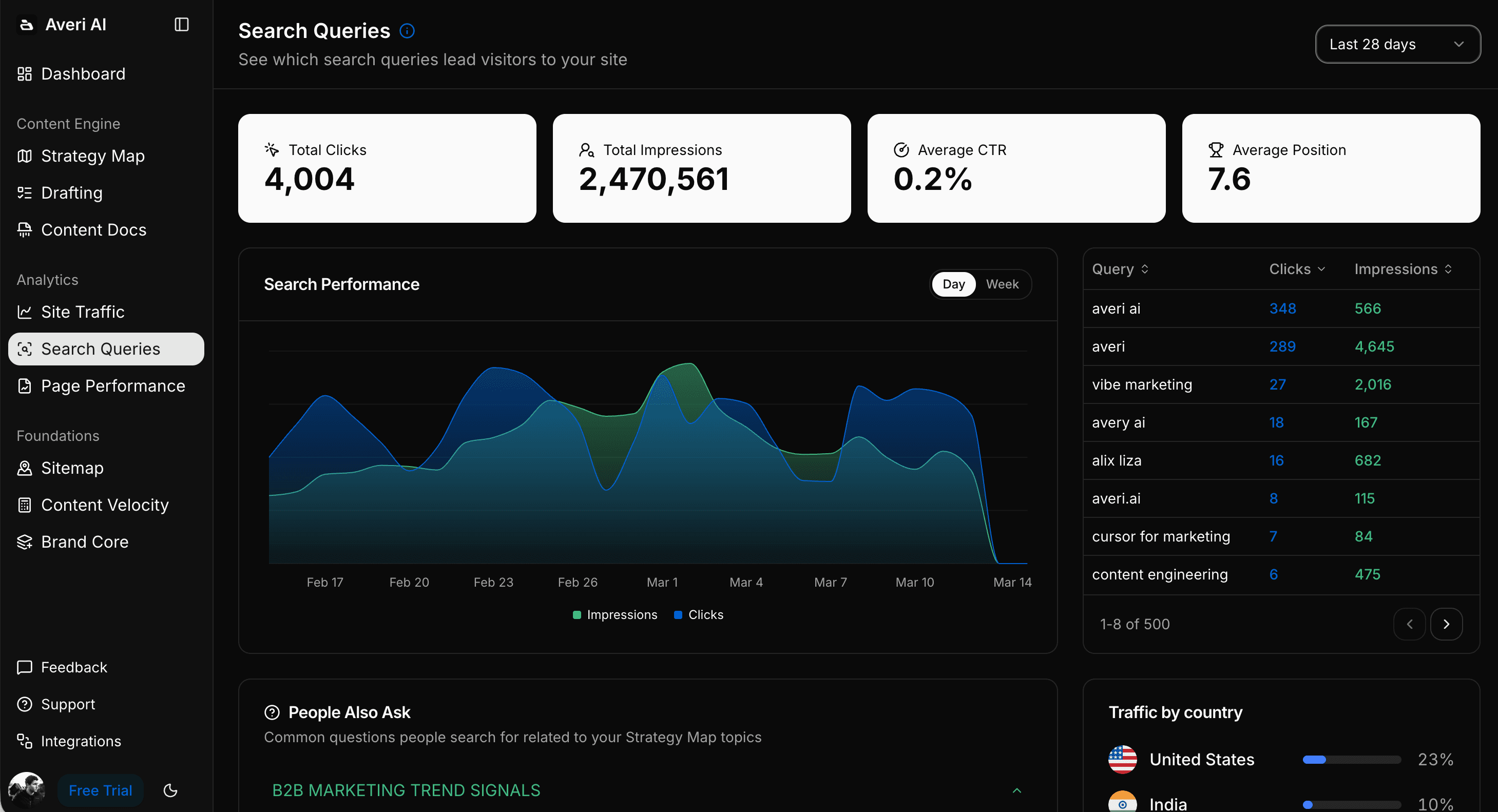
How Averi Operationalizes The Compounding Mechanic
The four compounding moves above describe what works. The harder question is how to actually run them as a sustained operating model rather than as a one-off campaign. This is where a content engine matters more than a tool stack.
A content engine is a packaged workflow that runs the production layer end-to-end, from strategy through publishing through analytics, while keeping humans in the loop at editorial checkpoints.
Averi is the content engine built specifically for founder-led B2B SaaS teams running the kind of workflow that compounds share of AI voice over 60–90 days. Here's how each capability maps to the compounding mechanics.
Brand Core Makes Cross-Source Consistency Operational
The cross-source consistency that drives RAG citation weighting only works if your brand is described the same way across every piece you publish. Most AI tools reset brand context every session, which produces drift toward generic AI voice. Averi's Brand Core loads your brand context (positioning, voice, ICP, category language, proof points) as input context before every draft, not as a filter applied after. The result is content that AI assistants can identify as part of the same source over time, which is the technical condition for cross-source consistency to compound into citation share.
Strategy Map Generates The Topical Depth That Compounds
Topical depth requires clustering 30+ pieces around 3–5 focused topics, not spreading 100 pieces across 50 disconnected topics. Most teams default to breadth because manual queue assembly is biased toward "what should we write next" rather than "what cluster are we building." Averi's Strategy Map generates topic clusters from competitive analysis and category positioning, surfacing the next 30–50 pieces that build depth on the topics your buyers actually search. This is the layer that prevents the most common share-of-voice failure mode: producing volume without compounding.
Content Queue Closes The Production-To-Performance Loop
The 60–90 day signal threshold only matters if you can sustain consistent output across the window. Manual queue management breaks down around month two because the editorial overhead of deciding what to write next compounds alongside the writing itself. Averi's Content Queue surfaces the next batch of pieces from a combination of cluster gaps, analytics signals, and competitive moves, so the production-to-performance loop runs without the operator deciding from scratch each week. The result is the cadence consistency the case studies (Gruns at 60 days, Averi at 12 months) all share.
GEO Scoring At Draft Time Produces Citation-Ready Structure
RAG retrieval rewards direct-answer formatting, fact density front-loaded in the opening, clear semantic structure, and schema that helps systems parse the page. Most AI drafting tools produce drafts that need 2+ hours of editorial cleanup to meet these conditions. Averi runs dual-layer SEO + GEO scoring during drafting, so every piece is checked against citation-ready structural requirements before it reaches editorial review. The drafts that ship from the workflow are pre-optimized for the retrieval conditions share of AI voice depends on.
The Averi Case Study
We operate Averi's own content engine the same way we built it for customers.
The results from 12 months of consistent output: 18,984% impression growth year-over-year, 12.6M total impressions, 30,254 clicks, a one-person marketing team, $0 paid acquisition. Branded search lift on "averi ai" producing 57.47% CTR at position 1.31. The full Google Search Console analysis is documented here.
The Averi outcomes aren't structurally different from the Gruns, Rootly, and Lago case studies. They're the same compounding mechanic running on a sustained 12-month time horizon rather than a 60-day burst. The pattern that produces share movement at 60 days is the same pattern that produces 18,984% growth at 12 months. The constraint isn't the tool. It's whether the workflow can sustain consistent output for the time horizon the compounding requires.
Common Mistakes Founders Make Measuring AI Share
Five mistakes that produce useless data or wrong strategic moves.
Wrong Query Set
The most common failure: teams pick queries that flatter their existing rankings rather than queries that map to buyer decisions. If your query set is full of pure branded queries or hyper-niche subtopics where you happen to rank well, your share-of-voice number will look great and predict nothing. The fix: include competitor-anchored, category-anchored, and use-case queries even when they're queries you don't currently rank for.
Only Tracking ChatGPT
ChatGPT is the highest-traffic assistant, but it's also the assistant where the largest tools are tracking. Coverage gaps in Perplexity, Google AI Mode, and Gemini routinely show up as missed share-of-voice movement. Track at least four assistants (ChatGPT, Perplexity, Google AI Mode, Gemini) before drawing conclusions about your category position.
Not Tracking Competitors
Tracking only your own brand produces a citation count. Tracking your brand plus three top competitors produces share of voice. The competitive denominator is what makes the metric strategically actionable. Skip this and you're back to vanity counting.
Measuring Weekly Instead Of Monthly
Weekly variance is noise. The underlying assistant indexes update on slower cycles, and weekly fluctuations rarely reflect real share-of-voice movement. Monthly measurement against the same query set produces signal. If you want a faster cadence, run a small subset (10–15 highest-value queries) biweekly while keeping the full query set on a monthly cycle.
Optimizing For The Score Instead Of The Pipeline
The final mistake: treating share of AI voice as the thing to maximize rather than as a proxy for pipeline impact. A team that optimizes purely for the score will publish content engineered for citation regardless of whether the citations correlate with revenue. Keep the metric anchored to buyer-intent queries that you've verified map to your pipeline. The score is useful as a leading indicator; it's a dangerous final metric.
Start manual. Move share. Then think about tools.
Averi is the content engine that produces the kind of compounding content output that moves share of AI voice over 60–90 days. $99/month for the Solo plan. 14-day free trial.
Related Resources
Measurement And Citation Tracking
How to Track AI Citations and Measure GEO Success: The 2026 Metrics Guide
What 12 Months of Google Search Data Taught Us About AI Overview Cannibalization
Foundational Concepts
Content Operations For Compounding Share
FAQs
What is share of AI voice in simple terms?
Share of AI voice is the percentage of citations your brand earns inside AI assistant responses (ChatGPT, Perplexity, Google AI Mode, Gemini) compared to your competitors, measured across a defined set of category-relevant queries. If across 100 brand citations on your query set, your brand appears 15 times, your share of AI voice is 15%.
How is share of AI voice different from traditional share of voice?
Traditional share of voice measures presence in channels you can buy into (paid media) or earn into (organic search). Share of AI voice measures citations inside AI-generated answers, where the assistant retrieves and decides whether to cite you as a source. You can't pay your way into AI citations directly, and position in the answer matters separately from share itself.
How do you calculate share of AI voice for free?
Run a defined set of 20–50 buyer-intent queries across ChatGPT, Perplexity, Google AI Mode, and Gemini. For each query, count citations per brand. Calculate your share as (your brand citations) ÷ (total brand citations) × 100. A spreadsheet handles the math. The whole workflow takes 3–4 hours weekly with no paid tooling required.
What's the right cadence for measuring share of AI voice?
Monthly for the full query set. Biweekly for a focused subset of 10–15 highest-value queries if you need faster feedback. Avoid weekly measurement; the underlying assistant indexes update on slower-than-weekly cycles and weekly fluctuations are usually noise rather than signal. 60–90 days is the minimum window to draw operational conclusions.
Which AI visibility tools are worth paying for?
It depends on your stage and need. Otterly AI ($29/mo) is the lowest entry point for solo founders. Peec AI ($99/mo) and SE Ranking AI Visibility ($119/mo) are mid-market with GA4 integration. AthenaHQ has the strongest enterprise case studies and credit-based pricing. Profound ($499/mo Lite to Enterprise) is the deepest-data option with up to 10-engine coverage. Stay manual until your query set exceeds 50 or you need integrated dashboard reporting.
Why does share of AI voice matter more than other AI metrics?
It's the only AI metric that combines a real denominator (competitive citation count) with a strategic numerator (buyer-intent query coverage). Raw citation counts are vanity; "AI visibility scores" are vendor-invented and don't translate across tools. Share of AI voice is reproducible from any data source and maps to pipeline because the query set is anchored to real buyer decisions.
How long does it take to move share of AI voice?
Realistic timelines: minor movement in 30 days, meaningful movement in 60 days, stable trend reading in 90 days. The fastest documented small-team movement is Gruns going from 2% to 12.6% share in 60 days. Teams that expect weekly movement give up before the metric stabilizes; teams that hold for 90+ days see compounding.






