How AI Agents Actually Read Your Content: Chunking, Embeddings, and Retrieval

6 minutes

TL;DR
🔁 The pipeline is RAG. Retrieval-augmented generation: an AI retrieves relevant documents, adds them to its context, generates an answer from them, and cites the sources. Your content has to be retrievable and extractable to be cited
🧩 Chunking is the core mechanic. AI systems split content into segments of roughly 128 to 1,024 tokens, because both embedding models and language models have token limits. The chunk, not the page, is the unit of retrieval
🔢 Embeddings turn text into coordinates. Each chunk becomes a vector — a list of numbers representing its meaning — stored in a vector database. Retrieval finds the chunks whose vectors sit closest to the query's vector
✂️ How you chunk determines what gets found. Semantic chunking, which draws boundaries at meaning, consistently outperforms fixed-size chunking that splits blindly by token count. Clean structure produces clean chunks
🎯 Self-contained passages win. A paragraph that only makes sense after three paragraphs of setup retrieves badly. A paragraph that delivers a complete answer on its own retrieves well
📐 Front-load the answer inside every section. If the answer is buried at the bottom of a section, the retrieved chunk may not contain it. Lead, then expand
🚫 None of it matters if the crawler can't see the page. Most AI crawlers don't run JavaScript, so client-rendered content is invisible before chunking even begins. The rendering gap, explained

Zach Chmael
CMO, Averi
"We built Averi around the exact workflow we've used to scale our web traffic over 6000% in the last 6 months."
Your content should be working harder.
Averi's content engine builds Google entity authority, drives AI citations, and scales your visibility so you can get more customers.
How AI Agents Actually Read Your Content: Chunking, Embeddings, and Retrieval
An AI agent never reads your page as a page. It breaks your content into fragments, converts each fragment into a list of numbers, and pulls back only the fragments that match a question. The page you carefully structured, with its narrative flow and its building argument, gets shredded into pieces and reassembled around someone else's query. If you understand that one mechanic, most of what people call "GEO" stops being mysterious and starts being engineering.
This is the foundational guide to that mechanic.
How retrieval-augmented generation actually works, what chunking is and why it exists, what an embedding really is, how a query finds your specific paragraph out of billions, and why the chunk rather than the page is the unit that gets cited. It's the technical layer underneath the broader shift in how agents read, how to write for them, and how buying is being rebuilt.
Most content advice for AI search skips this layer and jumps straight to tactics. The tactics make more sense once you've seen the machine. So we'll start with the machine.
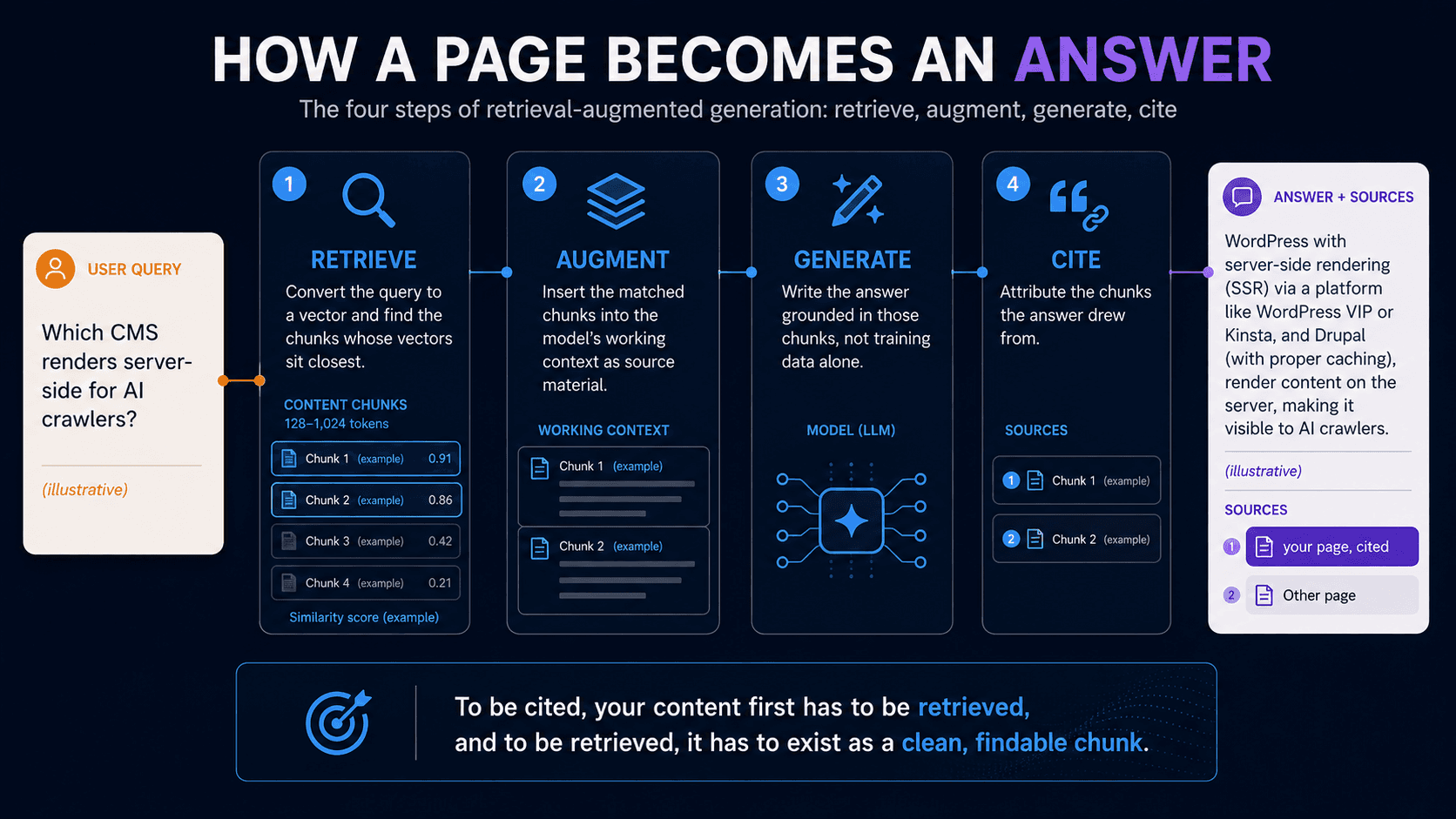
How Does an AI Agent Turn Your Page Into an Answer?
An AI agent turns your page into an answer through retrieval-augmented generation (RAG), a four-step pipeline: retrieve relevant documents, augment the model's context with them, generate an answer, and cite the sources used. RAG has become the dominant architecture for grounding language models in external knowledge, which means it's the system most AI answers about your category run through.
Here's the sequence in plain terms.
A user asks a question. The system converts that question into a vector and searches an index for the stored content fragments whose vectors are most similar. It pulls back the top matches, inserts them into the model's working context as source material, and the model writes an answer grounded in those fragments rather than in its training data alone. Then it attributes the fragments it drew from.
The implication is the whole game: to be cited, your content has to first be retrieved, and to be retrieved, it has to exist as a well-formed, findable fragment in that index. Ranking on Google is a related but separate question. RAG retrieval rewards extractable, well-structured passages, and the rest of this guide is about how to produce them.
What Is Chunking, and Why Does It Exist?
Chunking is the process of splitting your content into smaller segments before it gets stored and retrieved.
It exists because of a hard technical constraint: both the embedding models that encode text and the language models that generate answers have finite token limits, and they cannot process an entire long document in one pass.
Why chunking is necessary
Many embedding models have a maximum input of roughly 512 or 1,024 tokens, and cannot embed an entire document as a single vector. So a long page gets divided into segments, each small enough to encode.
Chunking serves two purposes at once: keeping segments inside the embedding model's input window, and ensuring each segment contains the focused information a query is looking for. A chunk that's too large mixes multiple topics and dilutes its relevance to any single query; a chunk that's too small loses the context needed to make sense.
The practical takeaway: your content is going to be cut into pieces whether you design for it or not. The only question is whether the cuts land on clean boundaries you controlled, or in the middle of an argument you didn't.
The main chunking strategies
There are several ways systems cut content, and they produce very different results. Fixed-size chunking splits by a set token count and is simple and fast, but it often breaks sentences mid-thought and mixes unrelated topics. Rule-based structural chunking exploits document structure such as headings, paragraphs, and HTML tags, which aligns boundaries with meaning better than blind splitting. Semantic chunking uses meaning to draw boundaries, producing segments that are thematically coherent rather than arbitrarily divided. Overlapping or sliding-window approaches let consecutive chunks share some text so context carries across the boundary.
The pattern across all of them: structure helps. A page with clear heading hierarchy and clean paragraph boundaries gets chunked along those boundaries, which means your sections survive as coherent units. A wall of undifferentiated text gets cut wherever the token counter happens to land.
What Are Embeddings, and How Does Retrieval Actually Work?
An embedding is a list of numbers that represents the meaning of a piece of text as a position in space. Retrieval works by converting both your content chunks and the user's query into embeddings, then finding the chunks whose positions sit closest to the query's position.
What an embedding is
Think of an embedding as coordinates for meaning. Text with similar meaning gets similar coordinates, so "how do I cancel my subscription" and "ending my plan" land near each other even though they share almost no words. Each chunk of your content is converted into a vector embedding and stored in a vector database, typically alongside an ID and metadata like the source document and creation date. The embedding is what lets the system match on meaning rather than on exact keywords, which is why modern AI search isn't fooled by synonym swaps the way old keyword search was.
How the query finds your chunk
When a query arrives, the system converts it into an embedding and retrieves the most similar chunks from the database as context for the model. "Most similar" means closest in that coordinate space. The system pulls the top handful of matches, and those are the only fragments of your content the model sees when it writes its answer. If your relevant passage didn't make the top matches, it doesn't exist as far as that answer is concerned.
This is why precision at the chunk level matters so much. Retrieval accuracy depends on chunk quality, and poor chunking is more often the cause of bad AI answers than the model itself. A focused, self-contained chunk that directly addresses a query will out-retrieve a longer, vaguer chunk that mentions the topic in passing.
Why the Chunk, Not the Page, Is the Unit of Citation
The chunk is the unit of citation because retrieval operates on chunks, not pages. The model never evaluates your whole page for relevance. It evaluates the individual fragments that surfaced in the similarity search, and it cites the ones it used. Your page can be excellent overall and still go uncited if the specific chunk that should have answered the query was buried, diluted, or split badly.
What this changes about structure
It inverts the old logic of a "great page." For traditional SEO, a thorough page that covered everything could rank well as a whole. For retrieval, that thoroughness only helps if it resolves into clean, individually-retrievable chunks. A 4,000-word page that's really thirty self-contained answers is a retrieval asset. The same 4,000 words written as one flowing essay with answers woven through long paragraphs is a retrieval liability, because no single chunk cleanly contains an answer.
This is the mechanical reason behind the editorial structure that performs in AI search: direct-answer subheads, sections that resolve a single question, modular blocks that stand alone. It's not a style trend. It's chunk design.
The self-contained passage test
The fastest way to audit your own content: take any paragraph out of its context and ask whether it still answers a question on its own. If it depends on the three paragraphs above it to make sense, it will retrieve poorly, because the retrieved chunk won't include that setup. The most effective chunking strategies preserve the connection between a chunk and the document's broader meaning, but you can't rely on the system to do that for you. Writing passages that carry their own context is the surest way to survive chunking intact.

What Makes a Chunk Retrieve Well?
A chunk retrieves well when it has clean semantic boundaries, leads with a direct answer, carries its own context, and uses structure the system can parse. These four properties are the difference between content that gets cited and content that gets passed over.
Clean semantic boundaries
Write so that each section addresses one question and resolves it. When the topic shifts, start a new section with a new heading. This gives structural and semantic chunkers a clean place to cut, so your sections survive as coherent units rather than getting spliced together or torn apart. Heading hierarchy is not decoration. It's the instruction set for how your content gets segmented.
Front-loaded answers
Lead each section with the answer, then expand. Because retrieval pulls the chunk that best matches the query, and because a chunk may not span your entire section, the answer needs to be near the top where it's most likely to land inside the retrieved fragment. A section that builds to its point over six paragraphs risks having the point fall outside the chunk that gets pulled.
Self-contained context
Repeat enough context that each passage stands alone. This feels mildly redundant to a human reading top to bottom, but it's what lets a chunk make sense when it's lifted out and dropped into an answer with no surrounding text. The best-performing approach to this is what some systems call contextual retrieval, where each chunk is enriched with document-level context, but the writer's version is simpler: name the subject in the sentence rather than relying on "it" or "this" referring back three sentences.
Structured data and tables
Use tables, lists, and clear formatting for anything comparative or enumerable. Tables are structured data in visual form, which AI extracts cleanly to build comparisons, while the same information buried in prose forces the model to infer the structure and often loses the nuance. A comparison written as a table with labeled rows retrieves and reconstructs far more reliably than the same comparison written as a paragraph.
How to Write So Your Content Chunks Cleanly
Putting the mechanics into practice comes down to a short, repeatable discipline. Write each section to answer one question. Put the answer in the first sentence or two, then expand with detail, examples, and evidence. Keep paragraphs focused on a single idea. Name the subject explicitly instead of leaning on pronouns that point backward. Use tables for comparisons and lists for sequences. Add a clear heading to every section so the boundaries are unambiguous.
This is the same structure that serves human readers who skim, which is the convenient part: the moves that help a chunk retrieve cleanly also help a person find what they came for. The two goals align more than they conflict, with one exception worth understanding. The discipline isn't writing for machines at the expense of people. It's writing with enough structure that both readers can extract what they need.
If you want the structural rigor applied automatically rather than checked by hand, that's what dual SEO and GEO scoring inside a content engine does: it evaluates whether a draft meets the chunk-level conditions for retrieval before the piece ships.
The Thing That Breaks All of This Before It Starts
Every mechanic in this guide assumes the crawler can read your page in the first place. Often, it can't. Most AI crawlers do not execute JavaScript, which means content that loads client-side is invisible to them before chunking, embedding, or retrieval ever happens. A Vercel and MERJ analysis of more than 500 million GPTBot fetches found zero evidence of JavaScript execution. You can structure perfect, self-contained, front-loaded chunks and still be completely invisible if they render client-side.
This is common enough and consequential enough to deserve its own treatment. We cover the rendering gap, the ten-second diagnostic, and the fix in a dedicated guide. Read it before you invest in chunk-level optimization, because there's no point structuring content the crawler never sees.
How Does Averi Build Content That Chunks Cleanly?
Averi builds content that survives chunking by enforcing the chunk-level conditions at the point of creation, instead of leaving them to chance or to a manual audit after publishing. Once rendering is handled, the day-to-day work is producing content that chunks cleanly piece after piece, and that is the work Averi is built for. The whole discipline in this guide, self-contained sections, front-loaded answers, clean semantic boundaries, explicit subject naming, is what Averi structures into every draft by default.
It is the brand layer for the agentic web: the system that keeps your content legible to the machine reading it in fragments.
Concretely, a few things work together. The content engine drafts in modular, single-question sections with the answer up front, which is the structure that produces clean, retrievable chunks. Dual SEO and GEO scoring then checks each draft against the chunk-level conditions, retrievable passages, direct answers, factual density, before it ships, so a buried answer or a context-dependent passage gets caught while it is still editable rather than after it publishes and goes uncited. And Brand Core keeps your naming and core terminology consistent across every piece, which is the entity signal that makes a retrieved chunk recognizable as yours.
We did not theorize this. We built Averi on Averi, running the exact chunk-level discipline this guide describes on our own content, and took it from a few thousand monthly impressions to over 12 million organic impressions across 12 months on a one-person team. The structure that gets a chunk retrieved is the structure we built the engine to produce.
None of this means structure replaces substance. Clean chunking is the floor, not the bar, and the substance still has to be yours. But the floor has to be reliable, and reliable is what an engine gives you that hand-checking every draft does not.
Make clean chunking your default. Averi structures every draft for retrieval and scores it before you publish, so the floor is handled and your effort goes to the substance. $99/month for Solo. 14-day free trial.
FAQs
How do AI models read web pages?
AI models read web pages through retrieval-augmented generation. They split content into chunks, convert each chunk into a vector embedding, store them in a vector database, and retrieve the chunks whose embeddings best match a query. The model then generates an answer from the retrieved chunks and cites them. It never reads the page sequentially the way a person does.
What is chunking in AI search?
Chunking is splitting content into smaller segments, typically 128 to 1,024 tokens, so they fit inside the token limits of embedding and language models and so each segment contains focused, retrievable information. The chunk, not the whole page, is the unit that gets retrieved and cited, which makes how your content is segmented a major factor in whether it gets used in AI answers.
What is an embedding?
An embedding is a list of numbers that represents the meaning of text as a position in space. Text with similar meaning gets similar coordinates, so a query and a relevant passage can match even when they share no exact words. AI search converts both your content chunks and the user's query into embeddings, then retrieves the chunks positioned closest to the query.
Why isn't my content getting cited even though it ranks well?
Ranking and citation are separate problems. Ranking evaluates your page as a whole; citation depends on whether a specific chunk of your content surfaces in retrieval and answers the query cleanly. If your answer is buried in a long paragraph, split across a section, or dependent on surrounding context, it may rank while still failing to produce a retrievable chunk. Entity recognition also matters: AI may skip you if it doesn't recognize your brand as a distinct entity.
Does chunking mean I should write shorter content?
No. It means you should write content that resolves into clean, self-contained sections, regardless of total length. A long page that's really thirty standalone answers is a retrieval asset. The same length written as one flowing essay is a retrieval liability. Write to depth, but structure that depth into modular sections that each answer a single question.
How do I make my content easier for AI to retrieve?
Write each section to answer one question, lead with the answer before expanding, keep paragraphs focused on a single idea, name subjects explicitly instead of using backward-pointing pronouns, use tables for comparisons, and give every section a clear heading. These moves create clean chunk boundaries and self-contained passages that survive retrieval intact.
Do all AI engines chunk and retrieve content the same way?
The broad mechanics are similar across engines, but the specifics differ in chunk size, retrieval weighting, and how aggressively they favor structure versus authority. The engines also differ in what they cite: ChatGPT cites product pages far more often than Perplexity, for example. The common ground is that all of them retrieve fragments rather than whole pages, so clean, self-contained chunking helps everywhere.
Related Resources
The Agentic Web Cluster
How Agents Read, How to Write for Them, and How Buying Is Being Rebuilt
The JavaScript Rendering Gap: Why AI Can't See Your Best Content
Writing for Humans and Agents at the Same Time: The Dual-Reader Playbook
Business-to-Agent (B2A): How to Prepare Your Brand for the Agentic Web
Foundational Concepts
Measurement and Application
Google AI Overviews Optimization: How to Get Featured in 2026
What 12 Months of Google Search Data Taught Us About AI Overview Cannibalization




