How Agents Read, How to Write for Them, and How Buying Is Being Rebuilt

6 minutes

TL;DR
🤖 Agents read in fragments, not pages. AI systems chunk content into 128–1,024 token pieces, embed each as a vector, and retrieve the chunks that match a query. The chunk, not the page, is the unit of citation. Detailed mechanics here
🚫 Most AI crawlers don't run JavaScript. A Vercel/MERJ analysis of 500M+ GPTBot fetches found zero JavaScript execution. A page can rank #1 on Google and be invisible to ChatGPT, Claude, and Perplexity at the same time. The rendering gap explained
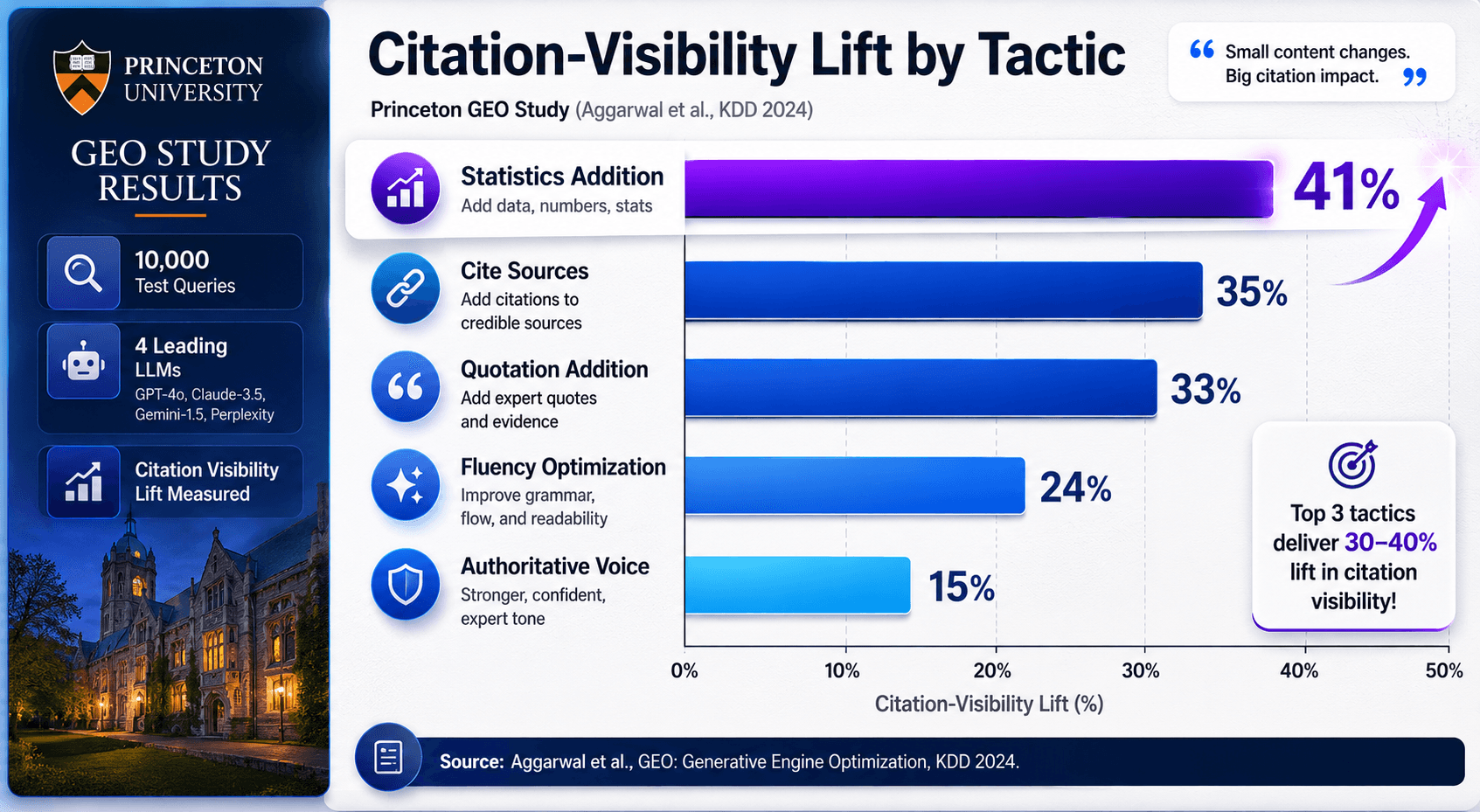
📊 Citation is earned through factual density. The Princeton GEO study found citing sources, adding quotations, and adding statistics each lifted citation visibility 30–40%, with statistics addition alone at 41%
✍️ You don't have to choose between humans and agents. The structural moves that help machines (modularity, direct answers, tables) also help humans skim. The one divergence, lived experience and POV, favors humans and signals originality to machines. The dual-reader playbook
🛒 Buying has moved into the machines. B2B buyers complete 70–80% of the journey before contacting sales, and AI-referred traffic converts far higher: one 42-site study found ChatGPT at 15.9% and Claude at 16.8% versus Google organic at 2.8%
🔌 Two layers are forming: citation and execution. Getting cited (GEO) is the crowded layer. Being executable to agents that act on a user's behalf (Business-to-Agent) is the open one. B2A and the agentic web
⏳ It compounds, so timing matters. Citation share is concentrating: the top 10 brands in a category now hold ~59.5% of AI citation share, up 293% in 60 days, because strong entity signals get reinforced in each model retraining

Zach Chmael
CMO, Averi
"We built Averi around the exact workflow we've used to scale our web traffic over 6000% in the last 6 months."
Your content should be working harder.
Averi's content engine builds Google entity authority, drives AI citations, and scales your visibility so you can get more customers.
How Agents Read, How to Write for Them, and How Buying Is Being Rebuilt
The web now has two reader populations, and they do not read the same way.
Humans skim for emotion, voice, and a point of view they can trust.
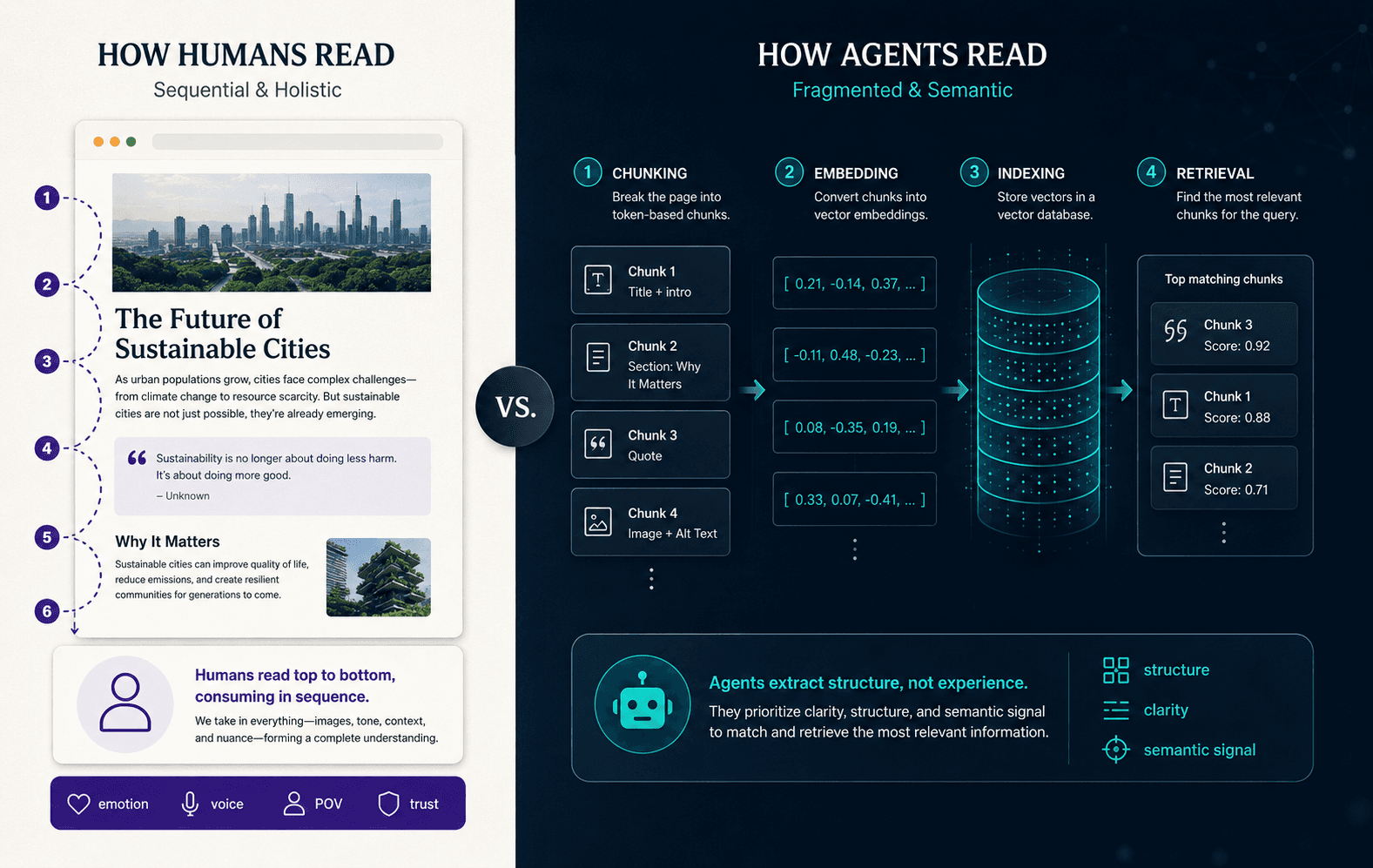
AI agents break your page into fragments, convert each fragment into a vector, and retrieve the pieces that match a query, never seeing your page as a page at all.
Most content is still written for one reader and accidentally optimized, or de-optimized, for the other. The brands that win the next phase of the web are the ones writing deliberately for both.
This is not a marketing-tactics shift. It is a structural change in how everything online gets found, understood, sorted, and bought.
Forrester's January 2026 survey of 18,000 global business buyers found AI tools now outrank vendor websites, product experts, and direct sales contact as meaningful sources of purchase information. 45% of consumers already use AI for at least part of their buying journey, per the IBM Institute for Business Value. The systems mediating discovery and purchase are being rebuilt around machine readers, and being legible to those readers is becoming the lever over the largest, least-visible phase of the buying journey.
This pillar covers the whole arc: how agents actually read content, what makes content citation-likely, whether you have to choose between writing for humans and writing for machines (you don't, and the reason is interesting), and how all of it ladders into a buying journey moving from AI-assisted research toward AI-executed purchase. Each section links to a deeper guide. Together they're the map for becoming legible to the next web.
How Do AI Agents Actually Read Content?
AI agents read content by breaking it into fragments, converting each fragment into a numerical vector, and retrieving the fragments most relevant to a query. They do not read a page top to bottom the way a person does. This is the single most important fact about writing for the agentic web, and almost everything else follows from it.
The mechanism is called retrieval-augmented generation (RAG). When you ask an AI assistant a question, it retrieves relevant documents from an index, adds them to its working context, generates an answer from them, and cites the sources it used.
The retrieval step depends on chunking: source content is split into segments of roughly 128 to 1,024 tokens, each converted into an embedding and stored in a vector database. At query time, the system pulls the chunks whose embeddings best match the query, not whole pages.
Two consequences shape everything.
First, each chunk has to stand on its own. A passage that only makes sense after three paragraphs of setup retrieves badly; a passage that delivers a complete, self-contained answer retrieves well.
Second, position inside a section matters: if the answer is buried at the bottom, the retrieved chunk may not contain it. Lead with the answer, then expand. The full mechanics (chunking, embeddings, semantic boundaries, and what they mean for structure) are covered in our deep-dive guide.
Why Can a Page Rank #1 on Google but Be Invisible to AI?
Because most AI crawlers do not execute JavaScript, and content that loads client-side simply isn't there when they read the page. This is the most consequential and least understood technical fact in AI visibility right now.
GPTBot, ClaudeBot, and PerplexityBot fetch raw HTML and extract text from the initial markup. They do not run scripts, wait for rendering, or make second attempts. A joint Vercel and MERJ analysis of more than 500 million GPTBot fetches found zero evidence of JavaScript execution, and even when GPTBot downloaded JavaScript files, it didn't run them. Only Google-Extended, Gemini's crawler, renders JavaScript, because it inherits Googlebot's rendering infrastructure. Every other major AI crawler reads raw HTML only.
The result: a client-side rendered page can rank number one on Google while being completely blank to every other AI search system. Product details, pricing, comparison tables, and FAQ answers injected by JavaScript are invisible to the engines now driving the overwhelming majority of AI referral traffic.
The diagnostic takes ten seconds: view the page source, or load it with JavaScript disabled. If your core content isn't in the raw HTML, agents can't read it. We break the whole problem down, including the fix, in the rendering-gap guide.
What Makes Content More Likely to Get Cited by AI?
Factual density makes content citation-likely: citing sources, adding statistics, and including direct quotations are the strongest measurable levers. This isn't speculation. It comes from the first peer-reviewed study of the question.
The Princeton GEO study, published at KDD 2024 by researchers from Princeton, Georgia Tech, the Allen Institute for AI, and IIT Delhi, tested nine content strategies across 10,000 queries. The five that boosted citation were citing sources, adding quotations, adding statistics, fluency optimization, and authoritative voice, and the top three each produced 30 to 40 percent improvements in citation visibility. Statistics addition alone lifted visibility by 41%, and combining strategies outperformed any single one by more than 5.5%.
There's a deeper driver underneath the tactics: entity recognition. The research shows brand mentions correlate with citations, but the actual mechanism is that brands mentioned consistently across credible, independent sources develop stronger entity signals, and stronger entity signals make citation more likely. Google's Knowledge Graph holds over 500 billion facts on more than 5 billion entities, and Gemini is trained on it, which is why ranking and citation are now separate problems. You can rank number one for a keyword and still go uncited if the model doesn't recognize your brand as a distinct entity.
Do You Have to Choose Between Writing for Humans and Writing for Agents?
No. The goals are mostly aligned, and the one place they diverge actually favors the human reader. This is the most important strategic point in the entire shift, because the market is full of tools selling the opposite assumption.
Humans read for emotion, narrative, and a point of view they trust. Agents read for structure, clarity, and semantic signal.
The naive conclusion is that you optimize for one at the other's expense.
The reality: the structural moves that help machines also help humans. Modular, self-contained sections help machines extract and help humans skim; tables are structured data in visual form that both parse fast; and leading with the answer lets machines categorize meaning and lets humans get what they came for. When you format for skimmability, you make the content easier for machines to parse at the same time.
The one genuine divergence is the experience layer, and it favors humans. First-person experience, lived detail, a falsifiable point of view: these are what humans trust, and the same signals tell the AI the content is original rather than synthetic.
So the resolution isn't a compromise.
It's a stacked requirement: be a rigid data architect for the machine and a credible, experienced human for the reader, in the same piece. The only thing that loses with both readers at once is generic, structureless, experience-free content. The full dual-reader playbook is here.
How Is AI Changing the Way Buyers Find, Analyze, Decide, and Buy?
AI is moving the buying journey into the machines, and increasingly from AI-assisted research toward AI-executed purchase. The change runs through all four phases.
Find
Discovery now starts inside AI tools rather than on vendor sites. 54% of B2B buyers use AI to research product information, 55% to compare vendors, and 47% to build internal business cases before engaging any vendor.
Analyze
The dark funnel is now mostly AI-mediated: buyers complete 70–80% of the journey before contacting sales, and 61% prefer a completely rep-free experience, with 57–73% of the journey happening in untrackable channels.
Decide
When buyers do click through from an AI surface, they arrive pre-qualified: one 42-site B2B study found Google organic converting at 2.8%, ChatGPT at 15.9%, and Claude at 16.8%, because AI compresses the research phase.
Buy
The execution layer is forming now: Gartner projects 90% of B2B purchases will be handled by AI agents by 2028.
The reframe: if the analysis phase happens inside an AI you can only influence by being citable and entity-legible, then getting cited correctly is the lever over the largest, most decision-shaping phase of the journey. Even when AI sends no click, brands cited in AI Overviews earn 35% more organic clicks than uncited brands.

What Is the Difference Between Getting Cited and Getting Chosen?
Getting cited means an AI mentions you as a source in an answer. Getting chosen means an AI acting on a user's behalf selects you to transact with.
These are two different layers, and almost the entire market is only working on the first.
The citation layer is GEO: structuring content so engines retrieve and cite it. It's getting crowded fast.
The execution layer is Business-to-Agent (B2A): being legible and actionable to agents that browse, evaluate, and transact for a user.
The infrastructure is forming in real time: Google added an llms.txt check to Chrome Lighthouse's new "Agentic Browsing" audit category in May 2026, and WebMCP, an open standard letting sites expose structured functions so browser agents can execute tasks directly, moved toward a public origin trial in Chrome 149.
The line that matters most comes from the agentic-commerce research: agentic AI does not reward brand familiarity alone. It rewards infrastructure readiness, and the supplier whose data, APIs, and flows are most legible at the moment of query becomes the selected option.
Being findable is starting to overlap with being executable. We map the B2A layer and how to prepare for it here.
Why Does This Favor Brands That Act Now?
Because citation strength compounds through model retraining, and the advantage concentrates. The brands building entity and citation strength now get reinforced in every subsequent model update; latecomers fight an uphill curve.
The mechanism is a flywheel: strong entity signals lead to more citations, which reinforce authority in the next training cycle, which produces more citations. The environment is also volatile. Semrush found Reddit's share of AI citations dropped from 60% to 10% between January and September 2025, which means measurement has to be continuous and the work has to be sustained.
This is the same compounding dynamic that drove our own content engine from a few thousand monthly impressions to over 12 million organic impressions across 12 months on a one-person marketing team. The pattern that produces citation movement at 60 days is the same one that compounds into category authority over a year. The constraint isn't the tooling. It's whether you start now and sustain it.
How Is Averi Building for the Agentic Web?
Averi is building the brand layer for the agentic web: the system that makes a brand legible to both readers, the human who reads for trust and the agent that reads for structure, in everything it publishes. The through-line of this entire shift is that legibility, not familiarity, decides what wins in an agent-mediated web.
That is the problem Averi exists to solve, and it is why we describe Averi as a brand layer rather than simply a marketing tool.
A tool helps you do a task. A layer is the thing your presence is built on across every surface a machine reads.
In practice, that means handling the structural floor so your effort goes to the substance above it. Brand Core keeps your entity signals, naming, and core positioning consistent everywhere, which is the consistency agents rely on to recognize you as a known entity instead of an ambiguous string. Dual SEO and GEO scoring checks whether a draft meets the chunk-level conditions for retrieval before it ships: the direct answers, self-contained sections, and factual density that get content cited. Publishing outputs clean, server-rendered content, so the rendering gap never opens and agents can actually read what you make. The structure is handled, which frees your real effort for the first-party data, lived experience, and point of view that make content un-swappable, the substance that is the bar.
We did not theorize any of this.
We built Averi on Averi, and the compounding climb described just above is our own: a one-person marketing team running the engine as its production system.
The mechanic the research lays out is the one we ran on ourselves, which is also why this pillar reads the way it does. It was produced through the same engine, structured for the same two readers, that we are describing.
And the foundation extends forward. The clean structure, consistent entities, and machine-readable output that win the citation layer today are the same things that make a brand executable to agents as the execution layer matures.
We are not claiming the agentic commerce layer is finished or that any brand has fully solved it.
We are saying the legibility you build now is the foundation it gets built on, and that Averi is designed for the web as it is becoming rather than the web as it was.
That is what a brand layer for the agentic web means: the system that keeps you readable, recognizable, and selectable as the reader on the other side shifts from a person to a machine acting for one.
Become legible to the next web
Averi is the content engine that builds the structural rigor machines need and the substance humans trust. Brand Core for entity consistency, dual SEO + GEO scoring for citation-ready structure, and a workflow that compounds authority over the 60–90 day window that moves the needle.
$99/month for Solo. 14-day free trial.
FAQs
How do AI agents read web content?
AI agents read content through retrieval-augmented generation (RAG). They split a page into chunks of roughly 128–1,024 tokens, convert each chunk into a vector embedding, store them in a vector database, and retrieve the chunks most relevant to a query. They never read the page sequentially the way a human does. The chunk, not the page, is the unit they retrieve and cite.
Do AI crawlers like GPTBot and ClaudeBot execute JavaScript?
No. GPTBot, ClaudeBot, and PerplexityBot fetch raw HTML and extract text from the initial markup without executing JavaScript. A Vercel/MERJ analysis of over 500 million GPTBot fetches found zero JavaScript execution. Only Google-Extended (Gemini's crawler) renders JavaScript, because it inherits Googlebot's infrastructure. Content that loads client-side is invisible to most AI engines.
What content changes make AI more likely to cite you?
The Princeton GEO study found the strongest levers are factual: citing sources, adding statistics, and including direct quotations, each lifting citation visibility 30–40%. Combining strategies outperforms any single one by more than 5.5%. Underneath the tactics, consistent entity signals across credible independent sources are what make a brand recognizable enough to cite at all.
Can the same content be optimized for both humans and AI?
Yes, and the goals mostly align. Modular sections, direct answers, and tables help machines extract and help humans skim simultaneously. The one divergence is the experience layer (first-person, lived detail, and point of view), which humans trust and which signals originality to machines. The only content that loses with both readers is generic, structureless, experience-free writing.
How is AI changing the B2B buying journey?
AI has moved the buying journey into the machines. Buyers complete 70–80% of the journey before contacting sales, and 54–55% use AI to research products and compare vendors first. When they click through from an AI surface they convert far higher than organic, because AI compresses the research phase and they arrive pre-qualified. Purchase itself is beginning to shift toward AI agents acting on a buyer's behalf.
What is Business-to-Agent (B2A)?
Business-to-Agent (B2A) is the emerging layer where brands make themselves legible and executable to AI agents that act on a user's behalf, browsing, evaluating, and transacting. It's distinct from the citation layer (getting mentioned in AI answers). B2A infrastructure includes llms.txt, WebMCP, and agentic-commerce protocols like UCP, A2A, and MCP. It's where "being findable" starts to overlap with "being executable."
Why is it urgent to optimize for AI search now?
Because citation strength compounds through model retraining and the advantage concentrates. The top 10 brands in a category now hold roughly 59.5% of AI citation share, up 293% in 60 days. Brands that build entity and citation strength now get reinforced in each model update; latecomers fight a concentration curve that steepens over time.
Related Resources
The Agentic Web Cluster
How AI Agents Actually Read Your Content: Chunking, Embeddings, and Retrieval
The JavaScript Rendering Gap: Why AI Can't See Your Best Content
Writing for Humans and Agents at the Same Time: The Dual-Reader Playbook
Business-to-Agent (B2A): How to Prepare Your Brand for the Agentic Web
Measurement and Citation
Foundational Concepts
Operational Workflow
The web is splitting into two reader populations. The brands that win the next phase write for both… rigid data architecture for the machine, real experience and point of view for the human. The structure serves both. The substance serves both. The only thing that loses is content built for neither.




