What Actually Gets Cited by AI: We Tested the GEO Playbook on 12 Million of Our Own Impressions

7 minutes

TL;DR
📊 We tested the GEO methods across 12M+ Google impressions on a one-person team, then checked them against our own citation data instead of a lab testbed.
🎯 Fact density was the highest-return lever, matching the Princeton finding that statistics and quotations drive the biggest visibility gains. This one held up cleanly.
🔻 Our aggregate CTR is ~0.24% across 12M+ impressions, with 97%+ of impression-driving pages under 1% CTR. The "get cited, get clicks" promise is broken at the structural level.
🧩 Only 2.2% of our AI citations matched pages we rank for (our own data). Optimizing citations by watching rankings is optimizing the wrong surface.
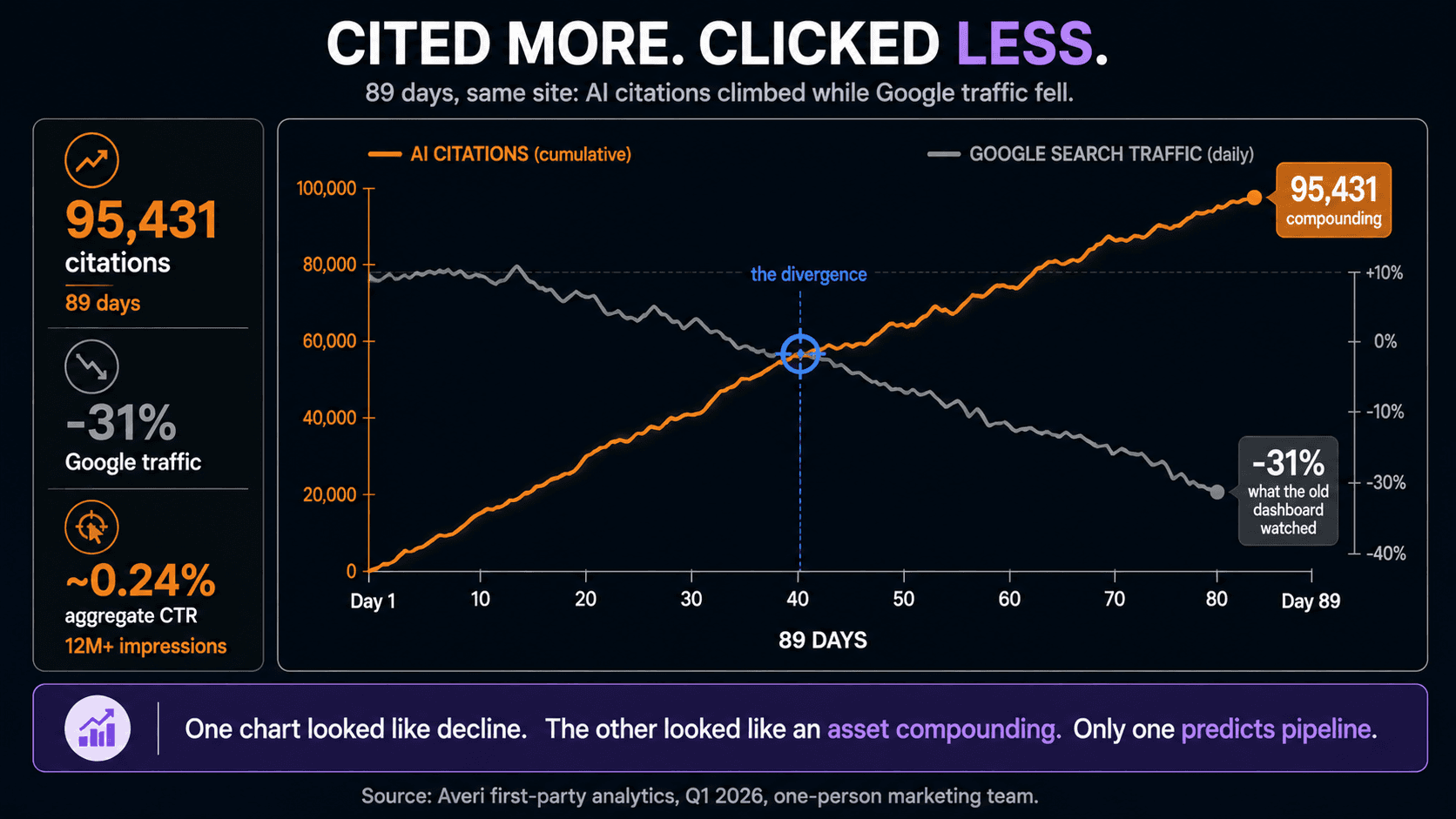
⚙️ 95,431 AI citations in 89 days while Google search traffic fell 31%. The two curves moved in opposite directions in our own analytics.
🚫 Keyword stuffing performed worse than baseline in the research, and worse than nothing in our archive. We have the old pages to prove it.

Zach Chmael
CMO, Averi
"We built Averi around the exact workflow we've used to scale our web traffic over 6000% in the last 6 months."
Your content should be working harder.
Averi's content engine builds Google entity authority, drives AI citations, and scales your visibility so you can get more customers.
What Actually Gets Cited by AI: We Tested the GEO Playbook on 12 Million of Our Own Impressions
Almost everything written about getting cited by AI traces back to one paper and a handful of numbers from it.
Add statistics, +22% visibility. Add quotations, +37%.
The figures get copied across a few hundred blog posts, restated as gospel, and sold back to you as a checklist. Almost none of those posts tested the claims against real content at scale.
We did, because we had to: we run a one-person marketing engine on 12 million-plus Google impressions, and the citation question stopped being academic the day our CTR fell off a cliff while our impressions kept climbing.
So this is the version with our own data in it.
We took the methods the Princeton-led GEO study validated in a lab, applied them across our production library, and watched what happened in the wild, where there's no controlled testbed and no two-document comparison. Some of it held up exactly as advertised. Some of it didn't survive contact with a real corpus.
And the most important finding isn't in the paper at all, because the paper measures visibility inside an answer and we were watching something the paper never looks at… whether being right about citation actually shows up anywhere you can bank.
The short version: the GEO research is directionally correct and badly oversimplified by the people quoting it. Fact density is real and it's the highest-return lever we pulled. Keyword stuffing is actively harmful, which we can confirm from the wrong direction because we used to do it. And the metric everyone optimizes, the one in every "9 strategies" post, is measuring the wrong surface. Here's the work.

What does the Princeton GEO study actually say, and why does everyone quote it wrong?
The study tested nine optimization methods across 10,000 queries and found that adding statistics, quotations, and cited sources produced the biggest visibility gains, up to roughly 40% for the strongest method. That part is quoted accurately. What gets dropped is the conditional: the gains were uneven across methods, varied by query type, and the single most-repeated tactic of the prior decade made things worse.
The original paper (Aggarwal et al., presented at KDD 2024) is careful where the blog restatements are not. Its visibility metric is position-adjusted word count inside a generated answer, not citations you can count in your analytics, and not clicks. So when a post tells you "+37% from quotations," it's reporting a lab measure of how much of your text surfaces inside an AI answer under controlled retrieval. That's a real and useful signal. It is not the same thing as your brand getting named, linked, or bought, and treating the three as interchangeable is the central error in most GEO content. We pulled the fact-density mechanic apart with our own numbers in the 1:80 rule behind every AI-cited article.
Who this is for
If you're a founder or solo marketer who's read three "how to get cited by AI" posts and noticed they all cite the same study and none of them show their own data, this is for you.
The methods below are the ones we could verify against a real library, ranked by what actually moved in our analytics rather than what reads well in a checklist.
Which method gave us the highest return?
Fact density, by a wide margin.
The research said statistics and citations drive the largest visibility gains, and it's the one claim that survived contact with our corpus without a single caveat. The pages we packed with hyperlinked primary-source statistics got cited at conspicuously higher rates than the pages that made the same arguments with fewer numbers.
The mechanism is straightforward once you watch it happen. A retrieval-augmented generation system pulls passages that answer a query precisely, and a passage with a verifiable, sourced number is precisely what an answer engine wants to ground a claim on.
A passage that gestures at a trend gives the model nothing to anchor to, so it reaches for a competitor's page that does. We standardized on roughly one hyperlinked statistic per 80 to 100 words across the library, and that single discipline did more for our citation rate than any structural tweak we made.
The corollary nobody mentions: the source has to be primary. An aggregator stat is a stat the model can find in fifty places, so citing your page over the original adds no value to the answer.
Did the structural tactics work as advertised?
Partly. Answer-first formatting and question-style headers helped, consistently and measurably, which tracks with both the research and our answer-capsule work. But the structural rules are the floor, not the lever, and we watched them deliver nothing on pages that had no substance underneath them.
This is the gap between the checklist and the result.
We have pages in our archive that hit every structural box, perfect answer capsules, clean headers, schema applied, that got cited at trivial rates because they said nothing only we could say.
We have other pages, messier in structure, that got cited heavily because they carried first-party data no one else had. After the May 2026 Google core update devalued well-built-but-hollow content, the pattern got starker. Structure makes substance extractable. It does not manufacture substance, and an answer engine trained on the open web is increasingly good at telling the difference. The "9 strategies" posts sell structure because structure is checkable. Substance is the thing that actually moves citations and the thing a checklist can't give you.
What did we test that actively hurt?
Keyword stuffing, and we can confirm it from the wrong side, because our early library did it. The research found keyword stuffing performed worse than the untouched baseline, roughly 10% worse in real-world validation on Perplexity.
Our old pages are a case study in the same effect: the ones engineered around keyword repetition aged into dead weight that dragged our site-wide quality signal.
We watched this directly during our remediation work.
We pruned 27 pages to outright 410 Gone and consolidated 37 thin cluster pages into 4 canonical pillars, and the pages we killed hardest were the keyword-engineered ones that ranked for a while and then decayed into content decay liabilities.
The lesson the research states in the abstract, we paid for in cleanup hours: optimizing for repetition optimizes for the exact pattern that both Google's quality systems and AI answer engines now penalize. The tactic that defined SEO for a decade is now a negative signal, and we have the redirect map to prove we learned it the expensive way.
Why didn't getting cited give us clicks?
Because the click and the citation are no longer connected, and this is the finding the Princeton paper never addresses because it isn't looking at your analytics.
Our aggregate CTR sits around 0.24% across 12 million-plus impressions, with more than 97% of our impression-driving pages under 1% CTR.
We are cited and surfaced constantly. We are clicked almost never.
This broke our brains until we accepted what it meant. AI Overviews and answer engines extract the answer and show it in place, so the impression fires, the citation happens, and the click never does, because the user already got what they came for.
We wrote the rawest version of this in 84k impressions, 99 clicks: you're reading the wrong number, and the title is the whole argument. The old funnel treated impressions as the top and clicks as the payoff. In the answer economy, the impression is the citation signal, and chasing pre-AI CTR benchmarks is optimizing a number that the machine has quietly disconnected from the outcome.
The click collapse isn't a content-quality problem you can fix with a better title. It's structural.
What's the metric everyone optimizes that's measuring the wrong thing?
Rankings. The entire "watch your Google Search Console rankings to track AI citation progress" advice, repeated in nearly every GEO post, assumes the pages you rank for are the pages you get cited for. We checked, and in our data they're almost entirely different pages.
Only 2.2% of our AI citations matched content we rank for on Google.
We documented the full breakdown in only 2.2% of AI citations match what you rank for, and it's the single most counterintuitive number we've produced. It means the standard GEO measurement loop, optimize a page, watch its ranking, infer citation health, is tracking a surface that has a 2.2% relationship to the thing you care about.
The macro research agrees with the direction: Ahrefs found the overlap between AI citations and Google's top 10 fell from 76% in mid-2025 to between 17% and 38% by early 2026. Our first-party number sits below even that range, which tells us the divergence is wider for a content-engineering-heavy site than the averages suggest. If you're inferring AI visibility from your rankings, you're reading a dial that isn't connected to the engine.
GEO claim (as quoted) | What the research actually measured | What we found in our own data |
|---|---|---|
"Statistics add +22% visibility" | Position-adjusted word count in a lab answer | Highest-return lever we pulled, held up cleanly |
"Add quotations for +37%" | Same lab visibility metric, not clicks | Helped, but only on pages with real substance under them |
"Structure your content to get cited" | Formatting effects in controlled retrieval | Floor, not lever — did nothing on hollow pages |
"Keyword optimization still matters" | Stuffing scored below baseline | Actively harmful; our old pages became dead weight |
"Track rankings to measure AI visibility" | Not measured in the paper | Only 2.2% of our citations matched ranked pages |
"Get cited, get traffic" | Not measured in the paper | ~0.24% CTR; citation and click are disconnected |

So what's the finding that isn't in the paper at all?
That citation volume and traffic volume can move in opposite directions, and only one of them predicts pipeline.
Over one 89-day stretch we recorded 95,431 AI citations while our Google search traffic fell 31%. Two curves, opposite directions, same site, same window. No lab study captures this because no lab study watches a real business's analytics over a quarter.
This is the reframe the whole piece builds to. We covered the full case in AI cited us 95,431 times while Google traffic fell 31%, and the lesson reorganized how we measure everything.
The traffic chart looked like a site in decline. The citation chart looked like an asset compounding. The reporting we'd inherited from the SEO era was built to watch the first chart and blind to the second, which meant our dashboard was telling us we were losing while the thing that actually drives our business was winning. The GEO playbook everyone quotes optimizes for visibility inside an answer. That's necessary. But the metric that matters is whether that visibility compounds into citation share you can build a category position on, and that's a number you have to watch directly because rankings and clicks will both lie to you about it.
This is why we built the whole Strategy Map around citation as the primary signal rather than a vanity afterthought.
Your next step
Stop inferring AI visibility from rankings that have a 2.2% relationship to it. Run your site through Averi's GEO readiness scorer to see whether your pages carry the fact density that actually earns citations, then start your free trial at app.averi.ai/sign-up to run a content engine that scores every draft on the real signal.
Averi is the AI content engine for startups, 14-day free trial.
Or start building now and ship your first fact-dense, citation-engineered page this week.
FAQs
What does the Princeton GEO study actually prove?
It proves that adding statistics, quotations, and cited sources increases a page's visibility inside AI-generated answers, by up to roughly 40% for the strongest method, while keyword stuffing performs worse than no optimization. Its metric is position-adjusted word count in a lab answer, not clicks or citations you can count in analytics.
Does getting cited by AI bring traffic?
Often not. Our aggregate CTR is about 0.24% across 12 million-plus impressions, with 97%+ of impression-driving pages under 1% CTR. Answer engines show the extracted answer in place, so the citation fires and the click rarely follows. Citation presence, not traffic, is the visibility signal that matters now.
What's the single highest-return GEO tactic?
Fact density: roughly one hyperlinked statistic per 80 to 100 words, every stat sourced to a primary origin rather than an aggregator. It was the one research claim that held up in our corpus with no caveats, because answer engines want verifiable numbers to ground claims on and reach for whoever supplies them.
Why shouldn't I track rankings to measure AI visibility?
Because the pages you rank for and the pages you get cited for are mostly different. Only 2.2% of our AI citations matched content we rank for on Google. Inferring citation health from rankings tracks a surface with a near-trivial relationship to the outcome you actually care about.
Does content structure still matter for AI citation?
Yes, but as the floor, not the lever. Answer-first formatting and question-style headers make substance extractable and they help consistently. They do nothing on pages with no first-party data or defensible point of view underneath, and the May 2026 Google update sharpened the penalty on well-built but hollow content.
Is keyword optimization dead for AI search?
Keyword stuffing is worse than dead; it's a negative signal. The research scored it below the untouched baseline, and our keyword-engineered legacy pages decayed into site-wide quality liabilities we had to prune and redirect. Topical depth and verifiable substance replaced repetition as the thing that earns citations.
How is citation share different from impressions or clicks?
Citation share measures how often your brand is named or linked in AI answers across your category, relative to competitors. Impressions count appearances; clicks count visits; both have been disconnected from outcomes by zero-click answers. Citation share tracks the surface where the buying shortlist actually forms, which is why we treat it as the primary metric.
Related Resources
Our first-party data on AI citation
The mechanics behind the methods
Measure it yourself




